NuoDB
Update solution on June 28, 2019
NuoDB looks relational and leverages SQL but isn’t relational under the covers. It was developed initially to support OLTP (online transaction processing) but by version 2.1 (2014) the company had started to offer a hybrid environment that not only supports transaction processing but also provides analytic capabilities. It should be noted that the product was designed like this from the outset. Under the hood, the product uses a distributed object model and data may be stored in flat file systems or block storage systems.
NuoDB particularly distinguishes itself because it offers a distributed database environment that can easily scale out, as opposed to scaling up. From a technical perspective, it may be deployed on-premises or in-cloud and it supports both hybrid and inter-cloud deployments.
Customer Quotes
“This investment and partnership demonstrates our strong belief in NuoDB’s strategy and technologies for next generation cloud-based technologies. Our partnership with NuoDB is strategic and strengthens our commitment to ensuring that our banking clients running Temenos software benefit from scale-out simplicity, elasticity and continuous availability, and that they can ultimately maximize the benefits of their shift to the cloud.”
Temenos
There are three major elements within a NuoDB deployment: an administrative tier, a processing tier and a storage tier. The first consists of “brokers” that provide functions such as load balancing and to which applications and users connect (via JDBC typically). There is also a NuoDB Insights, which provides monitoring capabilities. A major feature of NuoDB is the use of auto-administration and the ability to integrate with rules-based orchestration systems such as Kubernetes. You can define rules that automatically fire up additional resources under relevant conditions.
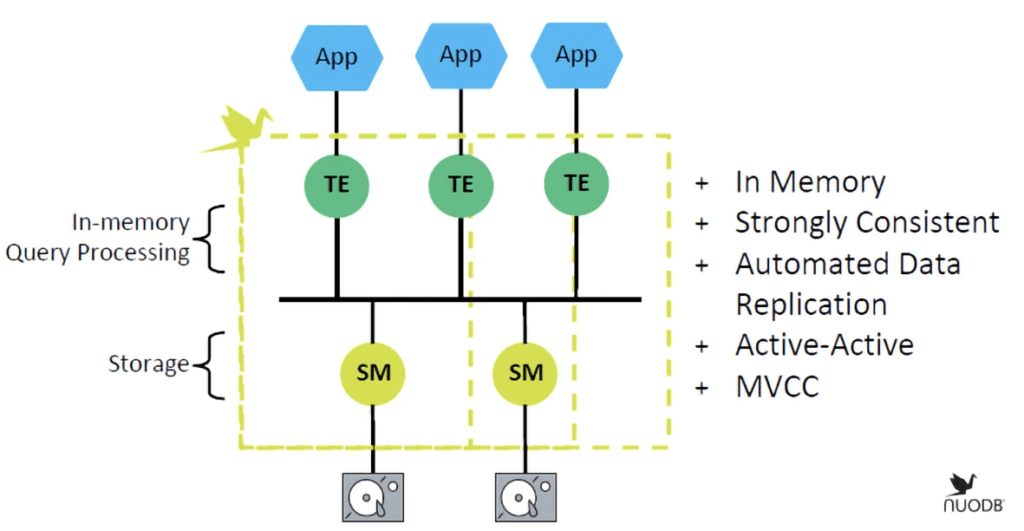
Fig 01 NuoDB transaction engines
As far as the processing and storage layers are concerned, these are illustrated in Figure 1. The former consists of transaction engines (TEs) that run in-memory (data is loaded on demand) and can be thought of as providing a loosely coupled distributed cache. Similarly, the storage layer consists of storage managers (SMs) where each storage manager within a “domain” has its own copy of the database so that, in effect, you have multiple physical active copies of the same database, but these are presented to the users (the transaction engines) as a single, logical instance. That said, NuoDB does support the option to partition data across storage managers but the default setting is for them to be replicas. Notably, you can have as many TEs and SMs as you like, and they can be scaled independently of one another. If required, nodes can be dedicated to analytic workloads.
Everything (data, metadata, indexes, schema and so forth) in NuoDB is known as an “atom” (sort of like an object but without object oriented properties such as polymorphism and inheritance) and transaction engines know where all the atoms are, whether in-memory or on disk, and when a transaction engine needs a particular atom it will retrieve it from the optimal source (its own memory, the memory of another engine or from disk). When changes or appends are made, that change is propagated to all other transaction engines using the same atom and is subsequently replicated to all the storage managers. Note, further, that NuoDB has a master-less architecture rather than either a master-slave or multi-master architecture, and this enables continued access to the database even in the event of multiple points of failure.
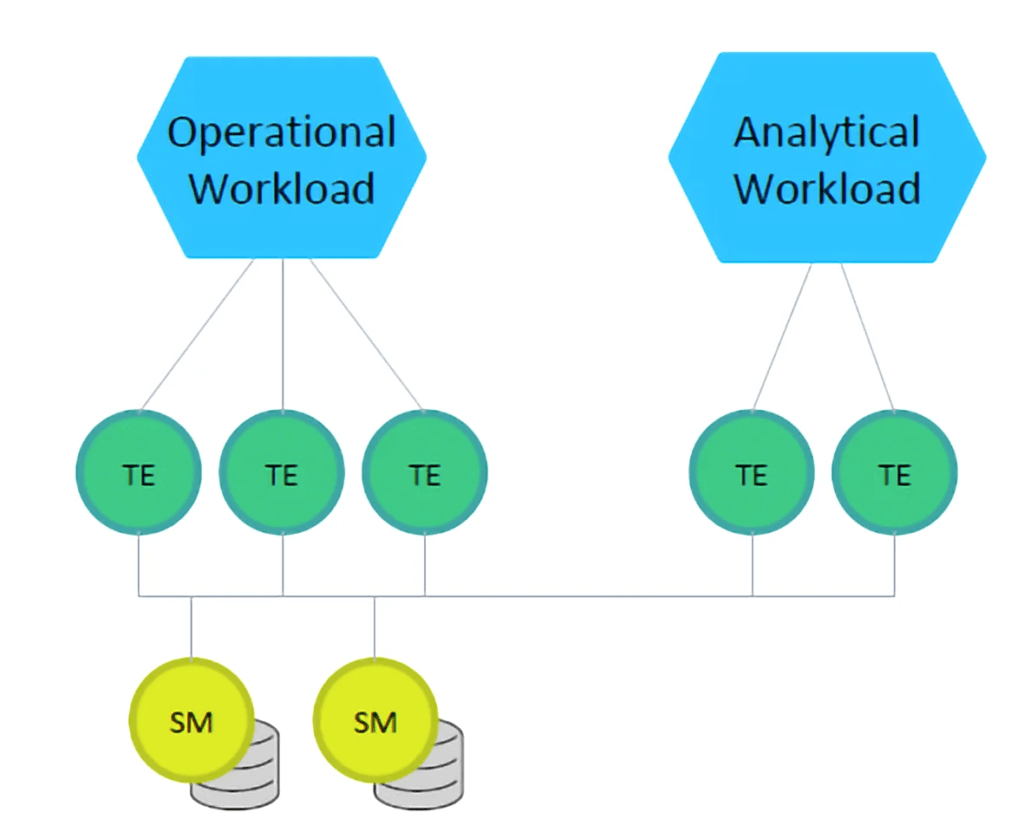
Fig 02 A typical NuoDB environment
From a hybrid processing perspective, Figure 2 represents a typical NuoDB environment with hardware isolation; meaning that operational and analytical workloads do not interfere with one another. Moreover, the implementation of MVCC (multi-version concurrency control) means that lock contention is avoided and that ACID guarantees are maintained. However, the architecture illustrated in Figure 2 supports environments where operations and analytics are distinct. There is also a class of hybrid environments where analytics, particularly machine learning or data science algorithms, needs to be embedded within operational applications. The company has told us that, in theory, NuoDB could support the import of relevant machine learning models but it has no examples of that use case within its customer base, and it does not have any specific support for third-party model libraries. On the other hand, it does support the ingestion of streaming data as there is a Kafka connector.
NuoDB primarily targets companies that want to migrate existing applications to what the company calls “Distributed SQL” environments. That is, elastically scalable, distributed, in-(multi)-cloud, container-based, SQL processing and applications. Hybrid analytic and transactional processing is a subset of that market that its direct competitors do not serve well, if at all.
The Bottom Line
NuoDB does not target what is sometimes known as “in-process” hybrid processing, but it is well suited to environments where real-time analytics is required in parallel to operational requirements.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community