IBM Test Data Management
Update solution on June 18, 2019
There are several IBM products that contribute to test data management. The most prominent belong to the IBM InfoSphere Optim range of products, including Test Data Management, Data Privacy, Test Data Fabrication and Test Data Orchestrator. These products handle data subsetting and masking, synthetic data generation, and test data coverage. InfoSphere Information Analyzer is also available as a data discovery tool that integrates with the Optim suite. Finally, IBM now provides data virtualisation via InfoSphere Virtual Data Pipeline, a white-label product created by Actifio, a close partner of IBM.
These products provide a range of connectivity options that most recently includes integration with Azure DB and Apache Hive. In addition, Optim is available as a native solution for z/OS mainframes.
Customer Quotes
“The IBM solution empowers us to keep our clients’ personal data safe, protecting the company’s reputation and preserving our customers’ trust.”
CZ
“Being able to test and iterate faster – using realistic, desensitized data across multiple applications – allows our teams to deliver leading-edge solutions that help our business run better and that bring greater security and convenience to our customers.”
Rabobank
IBM provides data discovery via InfoSphere Information Analyzer, as seen in Figure 1. This product profiles and classifies the data, and relationships between data, within your system. This includes the discovery of sensitive data. Both column names and data values are used to classify your data, and you can add custom field classifications if you wish or use the out of the box defaults. Using the product with Optim allows you to create meaningful subsets of your data, mask sensitive data, and automatically create representative sets of synthetic data.

Fig 1 IBM InfoSphere Information Analyzer
Subsetting is accomplished via InfoSphere Optim Test Data Management. Test Data Management allows you to extract representative, meaningful subsets of your data, which can additionally be right-sized by test type. For example, you might want a different sized subset for, say, unit testing as opposed to integration testing. Facilities are provided to refresh test data when required and also to compare data subsets. Multiple data sources can be integrated, and a single subset extracted from all of them. Note that although there are some performance issues on data sources without transactional indexes (such as Hadoop), these issues have been acknowledged by IBM and are currently being addressed.
InfoSphere Optim Data Privacy is a data masking product with several notable features, including affinity masking (for example, maintaining case), consistent masking across multiple platforms while preserving referential integrity, and semantic masking, though the latter is not easy to use and is not enabled for test data management. The company has also implemented in-database masking in a number of its environments and is actively extending this to others. This is supported by user defined functions. IBM is also actively integrating masking into other environments (for example, there is a Data Masking Stage in DataStage). You can use Optim, which supports both mainframe and distributed environments, for dynamic data masking but this is more usually the domain of IBM Guardium. Although Data Privacy does not support unstructured data in and of itself, IBM is able to provide this via their partnership with ABMartin.
InfoSphere Optim Test Data Fabrication, released in August 2017, offers synthetic data generation. It creates this data based on declarative rules that describe the desired dataset. Contradictory or unsatisfiable sets of rules are detected and highlighted. You can create these rules from scratch, but the more appealing option is to import metadata from Information Analyzer. In this case, a selection of rules will be created automatically that will generate synthetic data that is representative of the real data profiled by Information Analyzer. In addition, any column that Information Analyzer successfully classifies can be fabricated via built-in functions available in Test Data Fabrication.
InfoSphere Optim Test Data Orchestrator is a tool for measuring test data coverage that will analyse your test data, determine which possible combinations are missing, and present the results in a coverage matrix. Moreover, it allows you to create rules that express the smallest set of test data that is relevant to your system and will then then generate a coverage matrix purely for the data expressed by those rules. This provides a much more meaningful metric for test data coverage. Notably, the product is designed for collaboration, the idea being that the aforementioned rules will be determined by testers and subject matter experts working together.
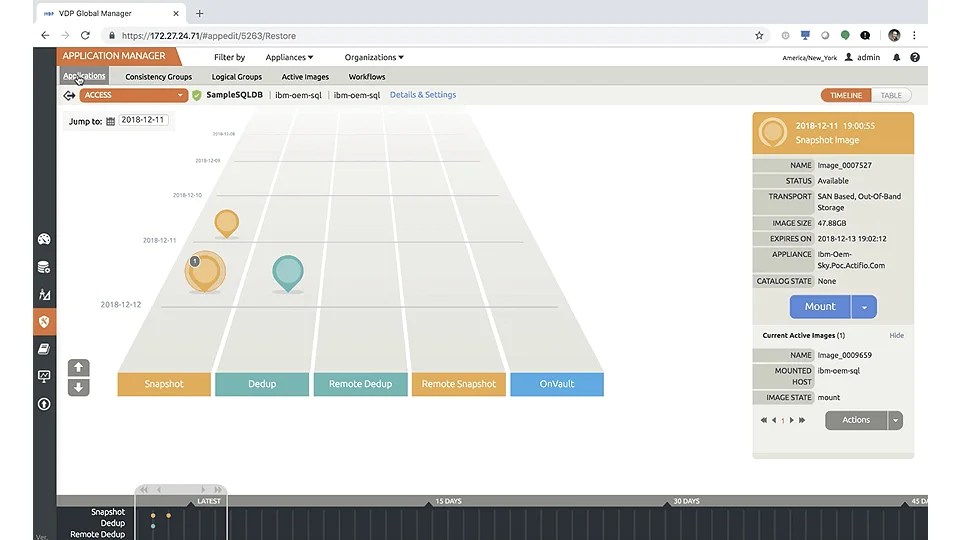
Fig 2 IBM InfoSphere Virtual Data Pipeline
Finally, InfoSphere Virtual Data Pipeline, introduced in December 2018 and shown in Figure 2, provides data virtualisation. This means that it can create and distribute virtual copies of your test data nearly instantly, whether that data consists of an entire (masked) production database, a masked or unmasked subset, or a synthetic dataset. These copies only store differences between themselves and the original data set, meaning that initially they take up no additional space (and what’s more, later increases in space tend to be minimal). Virtual Data Pipeline distributes these copies via self-service, and refreshes them automatically and on a schedule.
The most obvious differentiator for IBM’s test data management offering is its completeness: IBM is the only vendor we know of that is offering subsetting, masking, synthetic data and data virtualisation. Data virtualisation, in particular, is quite a rare capability, and IBM is the first vendor we have seen that offers it without almost exclusively focusing on it. Moreover, data virtualisation is a very powerful capability. The rapid provisioning it offers in combination with self-service can have a marked improvement on tester productivity, and it offers a very significant reduction in the space needed to store your test data.
It’s also worth noting the unique approaches taken by Test Data Fabrication and Test Data Orchestrator. Creating your synthetic dataset using declarative rules is useful, as is the ability to create data that is automatically representative of your production data. Likewise, paring down test data coverage to relevant test data coverage allows you to maximise coverage where it matters.
The Bottom Line
IBM offers a very complete test data management solution that is particularly appealing if you want to combine data virtualisation with either data subsetting or synthetic data generation.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community