Experian’s Data Quality Investments
Update solution on February 22, 2024
Experian Data Quality Suite is a full-function tool for data quality, from data profiling through to data cleaning, data matching, data enrichment and data monitoring. It recently expanded into data governance through its acquisition of IntoZetta in September 2023, which will be rebranded as Aperture Governance Studio as part of its Aperture software suite.
Experian’s data quality solutions have been widely deployed for customer name address validation. Indeed the company has been the market leader in this for some time. Over the last few years, Experian has significantly modernised and expanded its data quality software, with plenty of visualisation aids to ease the job of understanding and improving the quality of data. Recent new features include the automatic detection of sensitive data, visual associations between data, automated rule creation, and smarter data profiling.
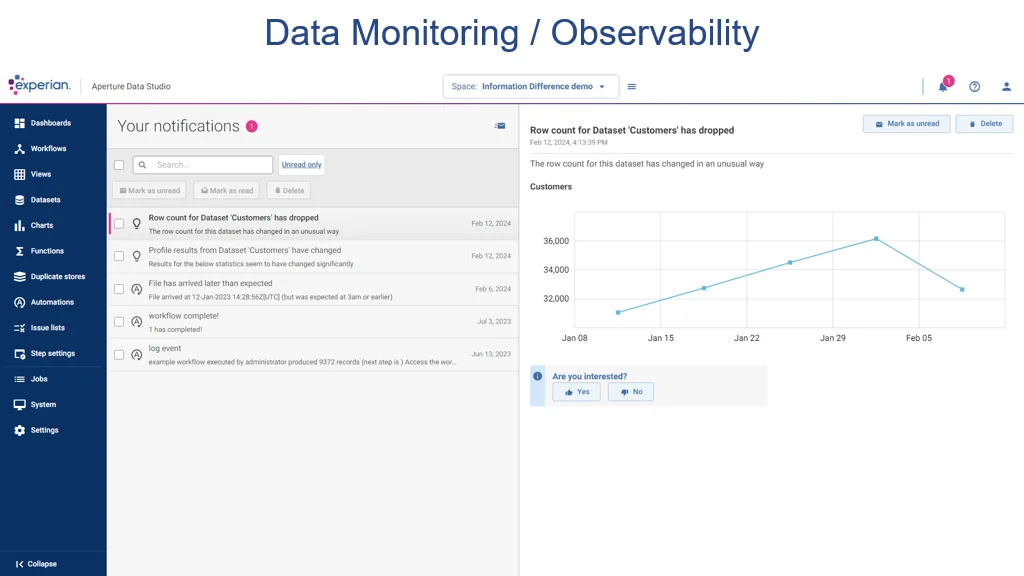
Fig 01 – Experian Data Comparison
Customer Quotes
“The more we use the tool the more possibilities for its use present themselves.”
Andreea Constantin, Data Governance Analyst, Saga
“We’ve managed to improve our customer data, reduce costs and provide a better customer experience – all while staying way ahead of the ROI. We’re thrilled with the first class products and services that have been provided; Experian Data Quality is clearly an industry leader.”
Steve Tryon, SVP of Logistics, Overstock.com
“By implementing a data quality strategy and using these tools in conjunction, CDLE has a more streamlined and efficient claimant process, explained Johnson. “When a person files a claim, we have the ability to verify in real time, which results in a faster process time”.”
Jay Johnson, Employer Services, CDLE
The Experian data quality software has a broad range of functionality. It can profile data to carry out statistical analysis of a dataset to provide summary information (such as the number of records and the structure of the data). The tool can also discover relationships between data and check on anomalies in the content. For example, profiling would detect whether a field called “phone number” had any records that did not match the normal format for a phone number or had missing data. The software can set up data quality rules that can be used to validate data, such as checking for valid social security numbers of valid postal codes. It can detect likely duplicates and carry out merging and matching of such fields, for example, merging files with common header names.
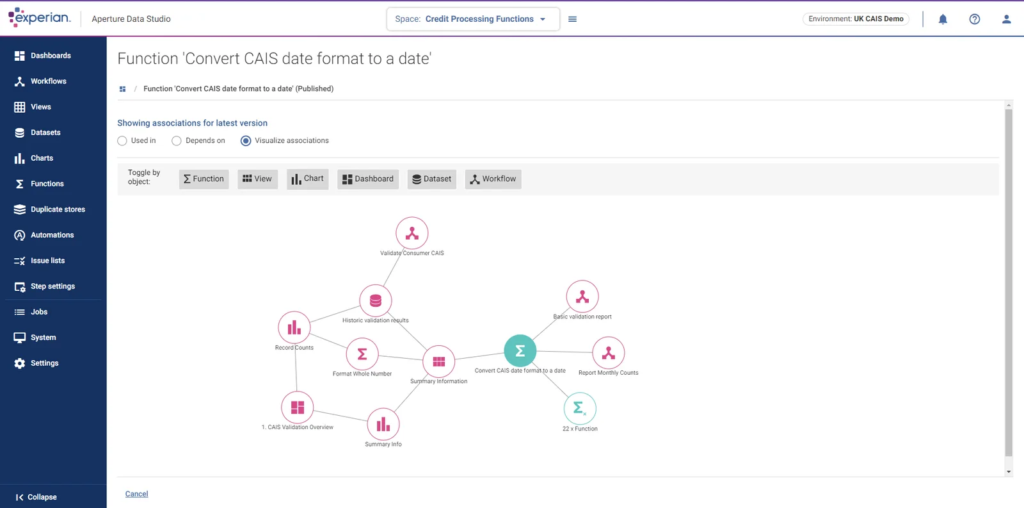
Fig 02 – Experian Visual associations
The software can enrich data too. For example, you might have a company with an HQ at a business address. As well as just validating the address, the software can add additional information that it knows about that business. At a basic level that might be something like adding a missing postal code, but it can be much more elaborate. Experian in particular has a rich vein of business data in its wider business, so could add information about the company such as the number of employees.
Data quality is a long-standing issue in business, with various surveys consistently showing that only around 30% of executives fully trust their own data. Poor data quality can have serious consequences, from the inconvenience of misdirected deliveries or invoices through to significant regulatory or compliance fines.
GDPR non-compliance can result in fines of 20 million euros or 4% of annual turnover in the EU, and there are numerous other regulatory bodies in the USA and elsewhere that apply fines for poor data quality in various industries such as finance (for example the MiFID II regulations) and pharmaceuticals (CGMP rules in the USA).
Another recent trend is likely to raise data quality higher up the corporate executive agenda. Companies, inspired by the success of ChatGPT and others in the public consciousness, are widely deploying generative AI technology in assorted industries. However, they are increasingly finding that they need to train such large language models on their own data (and operate private rather than public versions of such AIs for security reasons). It turns out that the effectiveness of such models is highly dependent on the quality of the data it is trained on, echoing the old “garbage in, garbage out” rule of computing. It is therefore important to assess and usually improve the quality of corporate data before a broad roll-out of generative AI technology.
The bottom line
Experian has a well-proven and comprehensive set of capabilities for data quality. It has expanded significantly in functionality in recent times, with its data governance capability the latest manifestation of this. With the excitement about deploying generative AI in corporations turning out to be heavily dependent on good data quality, vendors such as Experian should see renewed interest in their technology.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community