Curiosity Software Ireland Test Modeller
Update solution on February 5, 2020
Test Modeller is a test design automation product based on VIP, the Visual Integration Processor, a rapid application assembly framework developed by CSI. It provides functional, UI, performance, API and mobile testing via a model-based testing framework; advanced test data management capabilities, including synthetic data generation, allocation, subsetting, masking and cloning; and direct integration with a number of other testing products and vendors, including Eggplant, Tricentis, API Fortress and Parasoft. The product is entirely browser based, but can be deployed either in-cloud or on-premises.
Customer Quotes
“Gone are the days where you had to allot time for designing test cases. With modeller as soon as you create process model it automatically generates test cases using advanced coverage techniques.”
Information Technology & Services company
“Automated testing within reach and without writing the same tests scripts. VIP Test Modeller does enable an organization to seriously make a big left shift in their continuous development strategies.”
Transportation/Trucking/Railroad company
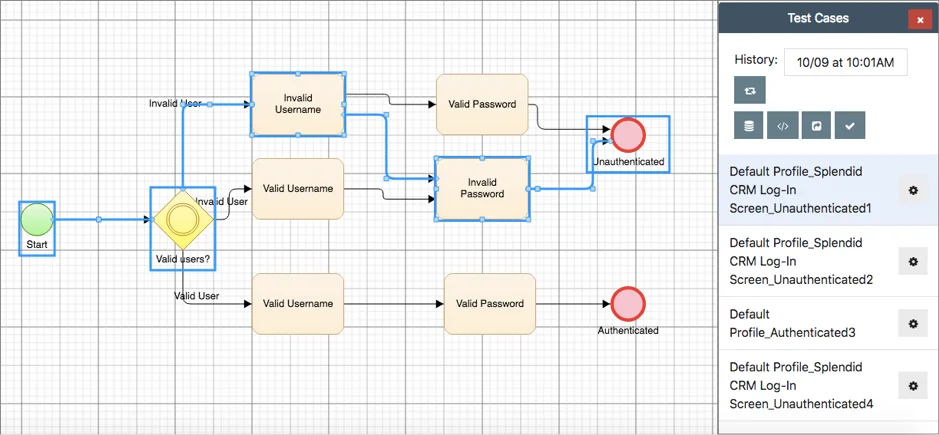
Test Modeller allows you to create a BPMN model for your system under test, as shown in Figure 1, which can then be leveraged to automatically generate testing assets. This model can be created manually using the built-in model editor, imported (for example, from a BPMN or Visio file), or built automatically using either existing testing assets, such as Gherkin feature files, or process mining via either Fluxicon or Dynatrace. Test Modeller also enables you to create user journeys by recording your interactions with your system. These are managed and analysed centrally and can also be used to automatically build your model. Furthermore, the tool can accelerate and guide model creation using its Fast Models feature, which automatically detects typical boundary values and valid and invalid test paths associated with an object under test.
Models can contain data variables, which will be found, parameterised, and populated with appropriate static data if your model was imported or built automatically. If not, you can add them manually. You can also opt to replace the static data in your model with dynamic synthetic data that will be generated automatically during test creation. Over 500 synthetic data functions are built-in, and you can create your own if necessary. Models can also be nested inside each other, enabling subflows. Importing models in this way is simple, and once a model is nested inside another, it is treated as if it were a part of that model. This makes managing nested models quite easy while creating a significant amount of reusability.
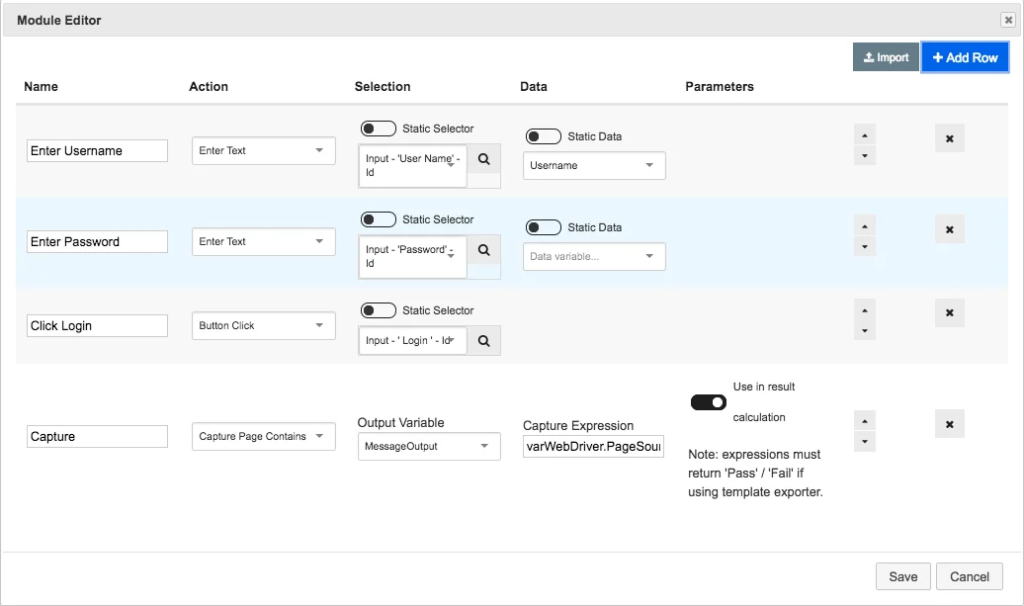
Fig 02 – The automation builder in Test Modeller
Models also contain an automation module for enabling automated execution. This is created automatically when a model is built, and otherwise can be created from scratch using the product’s automation builder (see Figure 2). This allows you to select which action to take, as well as which element to apply that action to, for each step in your testing process. Actions for Selenium, Appium, Parasoft, and a number of other tools are provided out of the box. You can also create your own, either manually or by using a code scanner (which are provided for Java, Python, C# and JavaScript) to automatically import any functions used by your existing test automation framework. Note that this will only work if your existing framework uses a Page Object Model architecture.
Once your model is complete, Test Modeller will automatically generate the minimal set of test cases for achieving 100% test coverage, as well as a corresponding set of executable test scripts. In addition, every part of your model can be tagged, and you can create coverage profiles for each tag in your model, enabling you to test different parts of your system with different levels of coverage. Test scripts can be executed within Test Modeller or exported into other products. Automated change management is also provided, and the framework can even “self heal” during test execution, allowing it to detect when something has changed, adapt, and keep your test(s) running. This enables highly resilient automation, particularly in regard to frequently changing UI objects.
Finally, for performance testing, Test Modeller integrates with Micro Focus LoadRunner, Apache JMeter, and Taurus. What’s more, it can implement performance testing actions from these frameworks as part of your existing model. Mobile and API testing work in much the same way, including integration with Appium, REST Assured, and the entire Parasoft stack.
Test Modeller’s most significant strength as a model-based test design automation platform is that is easy – and therefore quick – to use and to implement. For starters, it uses BPMN, which as a standard format will likely be familiar to your users, particularly nontechnical users such as business analysts. Creating your model is relatively easy: automatically creating it from existing test assets is, of course, the easiest method if those assets are available, but if not then recording user journeys and objects and building it from them is not difficult, and notably does not require any coding. Nested flows are handled elegantly, and the ability to overlay performance, API, and other types of testing on top of your model makes it much easier to implement those forms of testing alongside your functional tests. Several of these advantages should also help to enable collaboration. Consider, for example, that user journeys can be recorded by anyone, not just testers or developers, without requiring any expertise to do so. This means that, in principle, anyone in your organisation can contribute to your testing efforts simply by recording their usual interactions with your system.
What’s more, Test Modeller is highly effective at coexisting with an existing test automation framework. Being able to scan your code for existing functions and import them into your model is a particularly significant feature in this regard. Combined with the ability to export your test scripts back into your original test automation framework, or even into Git, it becomes easy to leverage the product to generate test cases and scripts automatically – thus saving a significant amount of time and effort – without otherwise altering your testing process. In addition, being built on VIP is a significant advantage, allowing Test Modeller to integrate with a long and highly extensible list of third-party products.
The Bottom Line
Test Modeller is an easy to use model-based testing framework that integrates extensively within the testing space. It is certainly worthy of your consideration.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community