Mage Data Test Data Management
Update solution on April 12, 2024
What is it?
Mage Data is a platform for governing and protecting your data and applications. It is scalable up to the enterprise level and can operate across legacy systems such as the mainframe, modern platforms like Snowflake and Databricks, and other data sources in between. It provides sophisticated sensitive data discovery alongside static and dynamic data masking, tokenisation, encryption, data subsetting, data monitoring, data minimisation, DSAR (Data Subject Access Request) automation, and more, offering a solution for data privacy that spans test data management while also reaching beyond it.
The platform can be hosted on-premises or in the cloud, and can work with both on-prem and in-cloud data sources. It supports a variety of data formats, including structured and unstructured data, and it integrates with an array of third-party products. Its connectivity has been bolstered by a recent replatforming effort, designed to better facilitate integration with new data sources and platforms. In addition, Mage Data is partnered with a number of relevant companies, including a grip of database virtualisation vendors, filling in one of the few holes in its line-up.
Customer Quotes
“We deployed Mage Data’s products for masking the sensitive and critical information of our clients and employees. It worked excellently for our onshore and offshore working models deployed in different countries.”
Banking firm
“A Perfect Solution For Data Masking – My team uses Mage Data daily to mask complex data seamlessly to be used in all phases of the development. Mage Data is efficient, flexible and able to adapt to our ongoing architecture changes.”
IT services firm
What does it do?
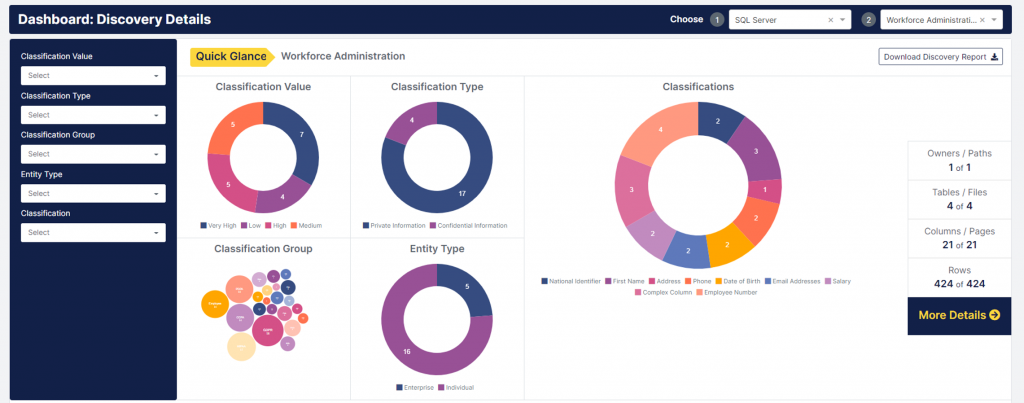
Mage Data’s sensitive data discovery capability profiles and classifies your data into data types, discovering sensitive data as it goes according to customisable discovery rules. Several methods are used for classification, including dictionary, pattern, data, and code matching. Any number of these can be applied at once to create an aggregate result that minimises false positives. Column sampling is used to minimise runtime, where samples are chosen to maximise coverage (for example, by only containing distinct values) and to be as representative of the underlying data as possible. AI- and NLP-driven entity recognition is available to identify sensitive data in free text. Classification results are stored in a reusable template that is leveraged throughout the platform. These results (or, more accurately, recommendations) come with confidence levels, as well as the reasoning that underpins them. If confidence is low, the process can be iterated. Approximately 85 classifications and discovery rules come preconfigured, in many cases built around commonly-applicable legislation, such as GDPR and HIPAA. Discovery is agentless, and can be deployed with little to no change to your existing processes.
Subsets can be created across all applications within your database (a horizontal slice) or a single application (a vertical slice). They are taken from cloned copies of your production data, and can be generated based on a variety of parameters, including pattern matching or a user-specified condition, location, or date (including a time slice: for example, the last 100 days).
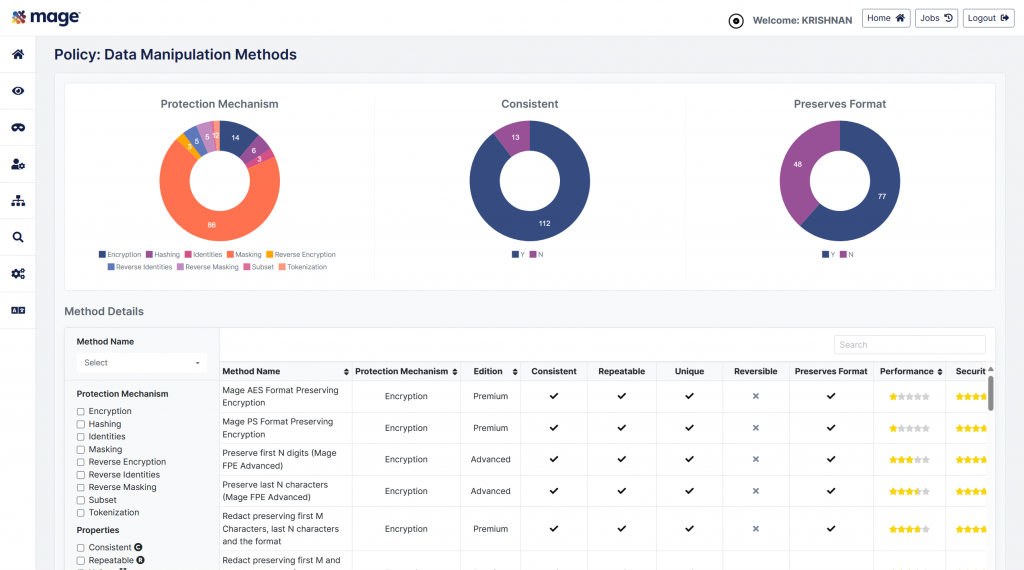
The product provides more than 115 static masking methods that run the gamut from anonymisation to encryption to tokenisation. These methods are built to maintain referential integrity as well as preserve important context (for example, keeping the distance between two locations constant, even when the locations themselves have been masked). It can mask data at rest, in-transit, or when it enters your system (“as it happens”), and in addition your data can be extracted, optionally subsetted, masked and loaded into a different location as part of an “ESML” process. At the same time, masking can be employed within the data store itself, meaning you don’t need to move any of the underlying data in order to mask it. Each classification discussed above is equipped with a default masking method that can be applied with little or no manual intervention, and the platform has a “test run” capability that allows you to simulate masking jobs without actually changing any of the underlying data, allowing you to identify and fix any resultant errors before executing the job for real. It also allows you to detect and mask/encrypt credit card information in log files, a requirement for PCI DSS 4.0 and DORA. Conditional masking – the ability to mask depending on the context – is provided, including location-aware masking that uses the physical location of the user as the masking condition, and it can be deployed in different parts of your environment, and using subtly different methodologies, to suit a variety of use cases. Mage Data additionally offers dynamic data masking, format preserving encryption, and tokenisation, based on user created templates that associate access rules and masking methods with sensitive data. Static and dynamic masking can be combined to offer concurrent, “blended” masking, as well as “on-demand” masking that extracts and stores statically masked data from a dynamically masked data source. Mage Data’s various masking capabilities can also be leveraged externally via REST APIs.
Mage Data offers synthetic data generation by way of “identities”. Identities are alternate, fake data sets (“universes of data”) derived from your real data. They are created by analysing the distribution of your data and calculating its statistical properties, then generating a new data set out of whole cloth which preserves the properties that you care for. This generated data can then be used as a completely desensitised (but still representative) replacement for your real data, adding noise if appropriate, within your testing environment.
A recent update has added several additional features to the platform. This includes a conversational (chatbot-driven) UI that provides access to discovery, anonymisation, and so on with a very low technical barrier, automating relevant behind-the-scenes tasks in the process; Extract-Mask-Load functionality, to create enterprise-scale anonymisation pipelines that protect data while moving it en masse; an embedded data catalogue, which bidirectionally integrates with other catalogue products; a secure gateway for ingesting files into your system, which will automatically detect and anonymise new files (including unstructured files, via AI) as soon as they land, then move them to a secure location; and log masking. This update also adds the ability to anonymise any sensitive data that is either fed into or comes out of your AI models, determined by enterprise-wide data policies. There are three main use cases for this: you can mask training data, so that your model doesn’t contain sensitive data in the first place; you can mask model responses, so that even when your model contains sensitive data it is not exposed to your users; and/or you can mask the sensitive data in your users’ prompts then unmask the corresponding data in your model’s response, allowing your users to leverage AI on sensitive information they have access to without ever letting it reach your model.
Why should you care?
Mage Data’s greatest strength is its best-of-breed, market-leading data discovery. In fact, in our opinion, it goes further than any other supplier in its facilities for discovering sensitive data. Code introspection, for example, is a relatively rare discovery feature that Mage Data makes excellent use of.
Mage Data also provides a unified (but modular) location for actioning on that discovery. These capabilities are less outstanding than discovery itself – it would be difficult for them not to be – but they are still substantial. Masking, in particular, is effectively automated via the masking methods attached to your classifications by default. Identities should also be mentioned as a solution for synthetic data that puts particular (and warranted) emphasis on preserving the statistical integrity of your data. What’s more, the greater integrability now offered by Mage Data means that individual pieces of its functionality can be effectively leveraged as point solutions, with its discovery, and to a lesser extent its anonymisation, capabilities being the standout in this regard.
Finally, Mage Data puts great emphasis on providing a low time-to-value, which can be seen in (for example) the number of premade rules and methods it provides. These efforts seem to be paying off: according to Mage Data, it only takes an average of 5 days for its clients to onboard their first system onto the platform, with further onboardings taking even less time. This is furthered by its web UI, which includes various ease-of-use enhancing features that make the platform easier to start being productive with, like visualisations, wizards, dashboards, and a “masking method handbook”. The platform’s newly added conversational UI also contributes to this.
The Bottom Line
Mage Data is a broadly capable, enterprise-ready data security platform (and consequently a formidable test data management solution) that offers notably excellent data discovery as well as highly capable static and dynamic data masking, subsetting, and synthetic data generation, producing “perfectly useful yet entirely useless” data sets. If you are struggling to find and protect your sensitive data – whether in a testing context or more generally – you should be looking at Mage Data, and this is especially true if you want a solution that you can get up and running as quickly as possible.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community