IRI FieldShield
Update solution on January 7, 2025
What is it?
IRI offers several products that are capable of data masking, namely FieldShield, DarkShield, and CellShield. Of these, CellShield is the most specific: it is designed to operate exclusively on Excel spreadsheets. DarkShield, conversely, is the most general, capable of searching for and masking PII and other sensitive data in a variety of different formats, including structured, unstructured, and semi-structured. FieldShield sits somewhere in the middle, focusing on structured data (primarily relational databases and flat-files, but also including spreadsheets, though it is less specialised than CellShield in regards to the latter). All three products are available individually, as a service, or as part of the IRI Data Protector Suite within the Voracity platform. They each offer data discovery capabilities in addition to data masking, and this can be used for a variety of purposes, not the least of which is to identify sensitive data to mask.
FieldShield, in particular, was first released in 2011 as a data masking solution that would “shield” sensitive data at the field level (hence the name). Historically, one of its biggest use cases has been anonymising data sets for use in test environments (which is to say, test data management), and this continues today. Moreover, FieldShield is built on the SortCL engine that also drives several other IRI products, such as CoSort. This provides FieldShield with various advanced functionality, including input phase filtering and complex field logic that can combine data masking with data cleansing, joining, reformatting, transforming, and more.
FieldShield can also be leveraged in real-time database replication scenarios via IRI Ripcurrent, a CDC (Change Data Capture) facility included in Voracity that refreshes target table rows whenever there are changes in the source table. By applying FieldShield’s masking functionality in Ripcurrent, sensitive data classes being refreshed or replicated to can be updated with masked data automatically and immediately.
FieldShield works on RDBs and MongoDB, ASN.1 CDRs, Excel sheets, and fixed and delimited files – typically on-premise, but increasingly often in AWS, Azure, and GCP environments. The product itself can be deployed on-prem or in the cloud, and can be consumed using the IRI Workbench or an API. It will readily integrate with other IRI products, including DarkShield for masking unstructured data and RowGen for generating synthetic data. In addition, FieldShield metadata is interoperable with other SortCL-driven products, notably Voracity for ETL et al., plus its RowGen, NextForm, and CoSort components. The latest FieldShield version, version 6, was announced in December 2024 and includes several new or updated features.
What does it do?
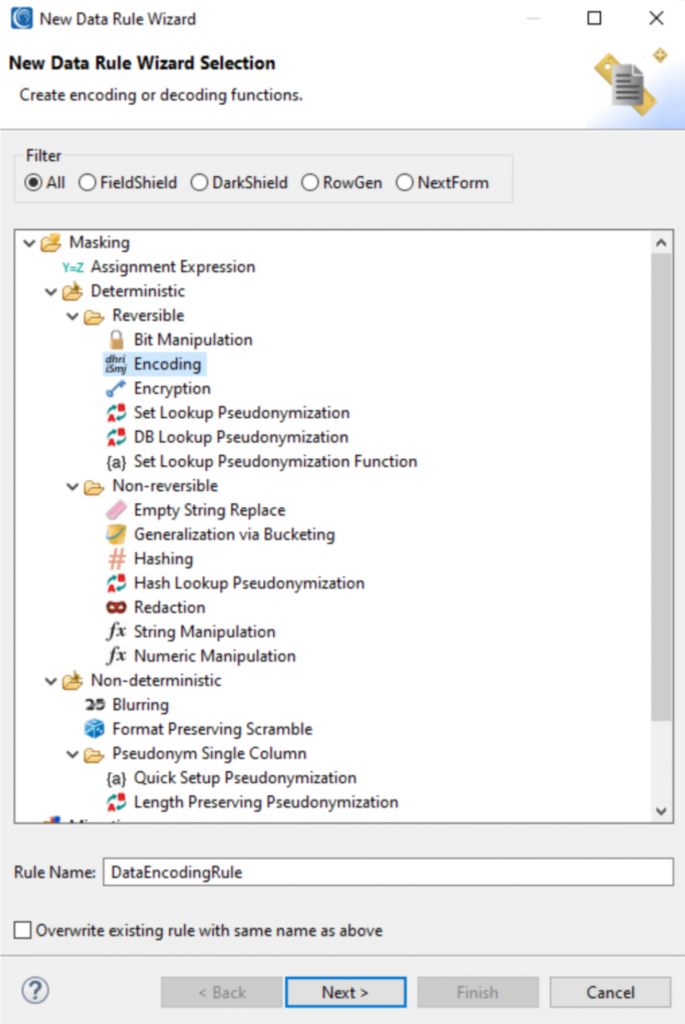
Masking in FieldShield is rule-based and powered by the aforementioned SortCL engine. A variety of out-of-the-box masking methods are available, including several dozen static masking functions that range between deterministic, non-deterministic, reversible, non-reversible, format-preserving, and so on (as shown in Figure 1). String and numeric manipulations are both available, and nested functions can be used to combine string manipulations and/or value lookups with other masking rules. Moreover, you can invoke DarkShield on free text fields from within FieldShield, scanning the contents of those fields and masking any sensitive text contained therein. Masked data is always kept consistent across multiple data sources, meaning that structural and referential integrity are maintained. As mentioned above, you can also leverage SortCL to combine masking with other data manipulations. For example, you can use it to action ETL processes simultaneously with data masking, which could be useful for, say, creating protected data sets for analytics.
FieldShield also provides a substantial data discovery and profiling capability, although unlike in DarkShield this is a separate process from its data masking. This enables you to search through and classify your data against a centralised library of either pre-configured or bespoke data classes shared between all of your IRI masking jobs and products, which can in turn be married to masking rules when they correspond to sensitive data. These rules are acted on at execution time, ensuring that the associated sensitive data is protected.
Considerations are made for performance: for instance, tables that have already been scanned will be skipped during repeated discovery phases, and you can choose to exclude specific tables or data classes from the process entirely. In addition, data classes can be grouped together at either a global or a project level, and these data class groups can be categorised by assigning them one or more sensitivity levels and/or applicable compliance regulations.
A range of discovery methods can be used as part of this process, including lookup value or pattern matching, column name matching, and dictionary matching. Moreover, any number of these methods can be used in concert with each other to improve the accuracy of your results, albeit at the cost of performance. There is a configurable matching threshold for discovery, allowing you specify how sure you want to be before settling on a result. Predefined methods for finding data protected by GDPR and HIPAA are available out-of-the-box.
FieldShield also comes equipped for handling quasi- or indirectly identifiable demographic data, which refers to data that does not identify an individual by itself, but can be combined with other, similar data in order to do so. The product can score the re-ID risk from, and anonymise, this kind of data in order to keep it compliant but accurate enough for analytic or marketing purposes.
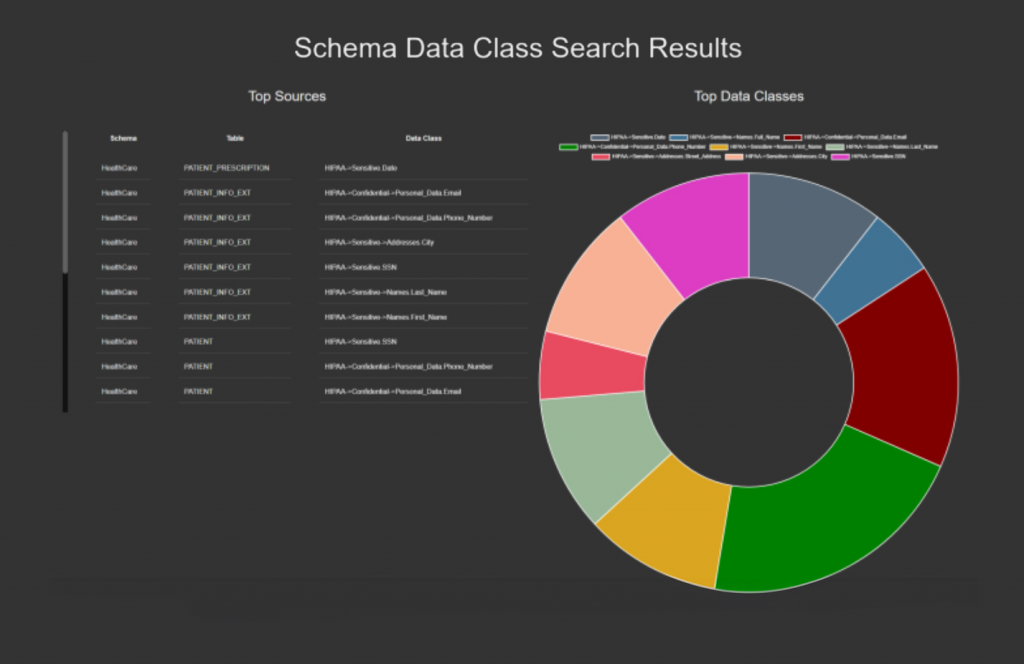
Fig 2 – HTML report produced by FieldShield
The results from FieldShield’s discovery process are summarised within an HTML report (a small sample of which is shown in Figure 2). This report provides a range of visualised information, including (but far from limited to) job performance (such as how long it took to run) and configuration (such as which data sources and classes of sensitive information were used). This can be used to copy the configuration and constraints present during a previous job in order to quickly reproduce it.
Why Should you care?
Ataccama provides an integrated platform ranging from data governance through to data quality and master data management. All this capability, other than a couple of very specialist areas such as name and address validation, is provided by software that was developed from the ground up to work together, rather than being patched together from various acquisitions. Consequently, Ataccama ONE is well suited for companies that want to implement a data governance solution that will not just be a stand-alone solution that documents the state of play with their data. Using this technology, they can move beyond this into data quality improvement and remediation, which will be a foundation for initiatives such as digitisation, and enable artificial intelligence initiatives with a sound basis of good quality data.
The Bottom Line
Ataccama ONE is well suited for companies that want to implement a data governance solution, but also want to move beyond this into actual data quality improvement and remediation, all using the same product suite.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community