K2view Test Data Generation and Synthetic Data Management
Update solution on June 4, 2025
What is it?
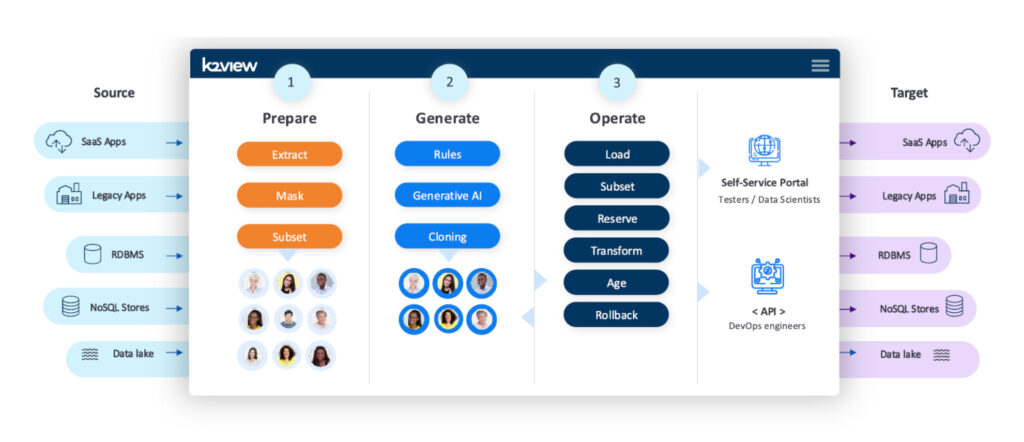
The K2view Data Product Platform provides a single, foundational platform upon which multiple specialised K2view products are offered, addressing a wide range of enterprise data management challenges. Key products include Test Data Management, Enterprise Data Masking, Data Pipelining, Customer 360, and Enterprise Data RAG. In particular, at least for this article, it provides a product – Synthetic Data Management (see Figure 1) – for synthetic data generation, offered in support of various software testing use cases.
One of the core capabilities of the K2view platform is its ability to organise your data into virtualised Micro-Databases, each one containing all of the information available on a particular business entity (such as a customer). This means that all data related to that entity is unified and consistently refreshed within a single (conceptual) location, making it far easier to manage that data. Notably, this capability is also used to help generate synthetic data.
K2view employs four methods for generating anonymised test data sets: data masking (and subsetting), entity data cloning, rule-based generation, and generation using generative AI. Data masking is provided by K2view Enterprise Data Masking (which we have explored in depth in a separate report), while the latter three methods, making up K2view’s synthetic data capability, aim to serve a range of test data use cases where data masking is not suitable (for instance, if production data is not available for use). Any number of these methods can be utilised together, further increasing the variety of use cases K2view is able to address.
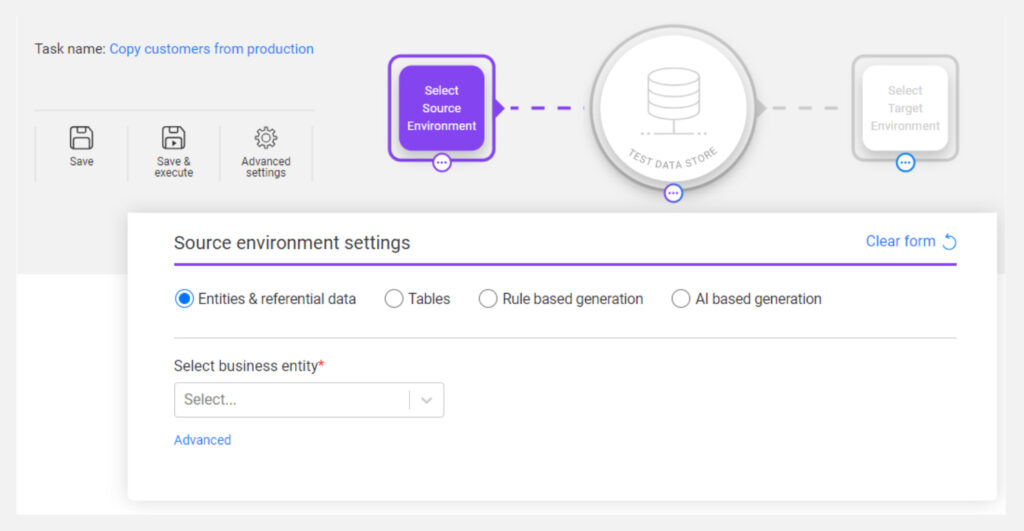
All of this functionality is available through a self-service interface (shown in Figure 2) and a series of APIs. It creates test data dynamically and without downtime, and can be used to generate both structured and unstructured data. Management capabilities are also provided, such as the ability to reserve synthetic data for your exclusive use as you create it, and aging the data after it has been generated. For this reason, K2view refers to its capabilities as synthetic data management, not just generation.
What does it do?
Data masking is the primary method through which K2view protects your test data. This is covered in- depth in this paper’s sister report, so we will not elaborate here, but suffice it to say that its capabilities are comprehensive and effective. In the context of test data generation, it is supported by the product’s subsetting functionality, which allows you to create a compliant subset of your business entities. Typically, entities are selected by specifying one or more business parameters that each entity is matched against. The business entity data model is beneficial here: entities are retrieved across all of your systems, and inherently retain referential integrity when used as part of a subset. Subsets can be masked using the platform’s usual methods.
Entity data cloning is a method for generating test data that is particularly useful for load and performance testing. It involves choosing a single entity – using a selection criteria similar to the subsetting process described above – and using it as a template to generate an entire test data set. This is achieved by repeatedly duplicating and masking the root entity until you have enough entities for your purposes. This is, in a sense, a simplified version of the data masking process, using one entity rather than many. Accordingly, it is both significantly faster and somewhat less secure, since the uniform nature of the creation process can increase the risk of reidentification. It also loses any kind of statistical distribution present in the original data, for obvious reasons. However, these disadvantages are of little to no importance for the load and performance testing in which entity data cloning finds it primary uses.
Rule-based data generation is K2view’s third method of generating test data. It is unique in that it does not rely on the presence of any production data. That said, the process should still be somewhat familiar, in that it uses the entity data model as a blueprint for generating synthetic data. Each field in the entity data model is associated with a business rule that is either automatically generated (based on the field’s classification, as defined in K2view’s data catalogue) or manually created to specify the ranges and distribution of values that your created entities should fall into. K2view will then generate synthetic entities that randomly take values within those ranges. This method is highly customisable, can be leveraged in almost any situation, and eliminates any risk of reidentification. On the other hand, setting up all of the rules needed will often be time-consuming and labour-intensive. Hence it is generally used in situations where production data is entirely unavailable, or where some particular data scenario needs to be tested but is not present in your production data (often alongside other methods).
Last, but certainly not least, generative AI can be used to analyse existing production data and generate synthetic entities from it, once again leveraging the entity data model that was described above and used in the other data generation methods. These entities will individually be entirely fake, but collectively approximate the original data set’s statistical properties and distribution while maintaining referential integrity. This is a significant strength of the method, as it allows its synthetic data to be used for meaningful analysis while still making reidentification very difficult, if not impossible. As with all AI-driven synthetic data, it relies on models that will require training (on masked data sets or subsets) before they can be used effectively. That said, model training capabilities are included in the product to ease this process as much as possible. In addition, while this method may fail to replicate particularly complex data scenarios, such as calculated fields, it can be supplemented with other methods (such as rule-based generation) to fill any gaps. Notably, the K2view platform includes reporting capabilities that compare the statistical properties of the synthetic data generated by this method and the original data it was based on. This can be used to validate said synthetic data, as its statistical distribution should be similar, but not identical, to the data it was derived from.
Why should you care?
K2view offers a variety of methods for creating test data sets, synthetic or otherwise, within a single product and to suit a wide variety of situations and use cases. Although data masking is clearly its primary mode of operation – and is offered at a very high degree of capability – it is equally clear that the company has invested significantly into its synthetic data generation and management functionality. The ability to leverage generative AI to replicate the statistical properties of existing production data within synthetic data sets is particularly notable, despite the caveats surrounding model training. We are also pleased that K2view is frank about both the pros and cons of the synthetic data methods it offers (such as the aforementioned model training) while offering capabilities to ameliorate the downsides where possible.
As ever, the business entity methodology K2view employs is also a significant boon, ensuring that synthetic data sets and test data subsets always maintain referential integrity and semantic consistency. In addition, the emphasis the company places on managing your synthetic data after it has been created (the management aspect of synthetic data management) is appreciated.
The bottom line
K2view provides a robust selection of tools for generating test data sets, including multiple kinds of synthetic data generation, in a single product. While we would not generally recommend using it solely for its synthetic data capability – its data masking functionality is too well-developed for that – it is certainly capable of playing that role if that is what you require.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community