
Teradata
Last Updated:
Analyst Coverage: Daniel Howard and Philip Howard
Teradata hardly needs an introduction: it is the longest established pure-play data warehouse vendor. The publicly traded (NYSE:TDC) 40 year old company has offices throughout the world and across all continents (except Antarctica), with 100s of proven vertical and enterprise customer use cases.
It was first incorporated in 1979, in the days when a “tera” byte of data was “big data”. It released the world’s first parallel data warehouse in 1984 and has been a (if not the) leader in the data warehousing space ever since. It became a public company in 1987 but was acquired by NCR four years later. Thereafter it regained independence from NCR in 1997 and, once again, became a public company in 2007. The company has made a number of significant acquisitions over the last decade, including Claraview, Aprimo, Aster Data Systems and others. In 2014 it acquired Think Big Analytics, which now forms the heart of Teradata’s consulting practices around big data, including AnalyticOps, and in late 2017 it spun off Starburst as a company focused on the Presto SQL Engine.
Teradata AI Unlimited
Last Updated: 21st November 2023
Teradata AI Unlimited is an attempt to give data professionals and developers of all types access to the tools they need to freely experiment with AI as quickly as possible while minimising the relevant costs. The expectation is that these efforts will, over time, lead to the implementation of more and better AI within your production systems and processes.
AI Unlimited gives your data scientists, data engineers, and so on access to a personalised instance of a Teradata environment, which they can play with to their heart’s content. If/when their efforts bear fruit, they can be implemented as part of your production platform. AI Unlimited instances can be created on-demand and without a long start-uptime, thereby acting as an accelerant for your AI development efforts. What’s more, due to the temporary nature of these instances, there is no need for data persistence, which can be (and frequently is) quite costly. Similarly, because they are non-production, you will often be able to relax what would otherwise be restrictive (and potentially obstructing) IT controls and data access limitations when working with AI Unlimited instances.
More technically, AI Unlimited is a serverless AI and ML engine that can be deployed on-demand to the cloud of your choice where your data resides. The engine itself is used for compute, and is supported by object stores that contain your data. It is most readily interacted with via Jupyter, which can be used as a control plane, although there is also a command line interface available that can be connected to a tool of your choice. GitHub is used to persist metadata and schema backups; most notably, this allows the product to provide a consistent (and customisable) look and feel for each user despite each personalised instance only existing temporarily.
In addition, Teradata has collaborated with Microsoft to deliver AI Unlimited on both Microsoft Fabric and the Azure Marketplace. In the former case, integration with the Microsoft ecosystem will be as tight as you would expect, such that you can quickly and easily leverage AI Unlimited functionality, like spinning up a new cluster, from within the Fabric platform. The Azure marketplace offering, in contrast, is self-service, and relies on more direct interaction with the infrastructure described above. In either case, AI Unlimited seem like an obvious win if you are serious about innovating with AI.
Teradata AnalyticOps
Last Updated: 17th January 2020

Fig 01 - Teradata AnalyticOps conceptual architecture
Teradata is a pioneer in this space. The company does not yet provide an encapsulated AnalyticOps or model management product per se (and thus there is no “product” for us to review) but nevertheless it is acutely aware of the growing importance of these areas. Accordingly, Teradata offers an AnalyticOps Accelerator, a software and services offering comprised of best practices, proven design patterns, and tried-and-tested code, which jointly enable the client to implement an AnalyticOps Framework to support robust and continuous operationalisation of analytics, as illustrated in Figure 1. These assets have been taken from successful real-world projects and Teradata services, and genericised so that they may be reused and customized to other client settings. The services and technical IP of the AnalyticOps Accelerator are designed to help organisations get up and running with AnalyticOps and model management very quickly, accelerating deployment and increasing return on investment. While the company has told us that it intends to productise some or all of its AnalyticOps capabilities, it has not done so yet. Thus, the AnalyticOps Framework is available primarily via a services engagement.
We should say that we have seen a demonstration of what can be achieved using Teradata’s AnalyticOps Framework, and it was impressive. It included model performance monitoring and management, job management (but not approval workflows, though the company has integrated approvals since the demo we saw), model comparisons (champions and challengers), and the ability to examine model history and track changes. The company is not providing bias detection (it, perfectly reasonably, sees this as a part of the data science function) but does have explainability on its roadmap.
Teradata ClearScape Analytics
Last Updated: 1st June 2023
Mutable Award: Platinum 2023
Teradata Vantage is a connected, multi-cloud data platform for enterprise analytics that aims to provide a unified solution for all of your data sources.
It delivers advanced analytics and machine learning functions, and makes it easy for analysts, data scientists, and line of business users alike to harness these functions to address business opportunities. Its core value proposition is that it will help you to operationalise your AI by improving the productivity of your data scientists, training your models at scale, and situating those models within a concrete business context that directly links them to business outcomes.
VantageCloud – formerly Vantage in the Cloud – is a version of Vantage that operates as a cloud analytics and data platform, offering the aforementioned capabilities as part of a cloud deployment. VantageCloud comes in two versions: VantageCloud Enterprise and VantageCloud Lake. VantageCloud Enterprise is similar to the previous Vantage in the Cloud offering, and accordingly is suitable for mixed, business-critical enterprise workloads. VantageCloud Lake, on the other hand, is a new development that has been designed to enable exploratory analysis and that can operate wherever your data already exists. Both Enterprise and Lake VantageCloud offerings can be used standalone or in conjunction with one another, and both are built on the same underlying tech stack (which is itself very similar to the stack used by on-premises Vantage deployments).
ClearScape Analytics refers to the analytic capabilities available as part of the Vantage platform, including VantageCloud and deployments thereof. It is comprised of more than 150 in-database functions, open and connected integrations/APIs, and features enabling the full-scale activation and operationalisation of analytics. In particular, this means that the same analytics functionality underpins all Vantage deployment options.
For this report we will be focusing on ClearScape Analytics, although we are also publishing a sister report that covers VantageCloud Lake.
ClearScape Analytics is an encapsulated set of functionality that is deployed alongside (and packaged as part of) other Vantage products, most notably VantageCloud Enterprise and VantageCloud Lake. This allows ClearScape Analytics to serve as the core analytics capability supporting any and every Vantage product. That said, it is worth noting that VantageCloud in particular provides an open analytics framework with which you can leverage your own or third-party analytics functionality rather than ClearScape Analytics.
In terms of concrete functionality, ClearScape Analytics supports a wide variety of languages for analytic purposes, most notably Python and R as well as Jupyter Notebooks, SageMaker, Azure Analytics, and more. Additionally, addon libraries for Python and R are available that allow you to generate SQL from your Python and R code and use that to run your queries. Parallel computation is available. It also offers graph capability, support for machine learning, and 150+ built-in analytical algorithms in support of advanced analytics and machine learning at scale. This includes time-series and temporal functions (over fifty of which are provided out of the box) that, along with comprehensive geo-spatial support, are combined in what Teradata calls “4D Analytics”. For machine learning in particular, you can either build models using ClearScape Analytics or import existing models from, for example, Dataiku, Spark, SageMaker, R, or Python. These models are converted to PMML (Predictive Model Markup Language), ONNX, MLEAP or an H20.AI model during the import process, and can then be executed in parallel just as your queries can.
In addition, ClearScape Analytics ModelOps is provided as a comprehensive means to manage your AI/ML models within Teradata Vantage. It aims to address the complexities associated with the deployment of AI/ML models, making it easier for you to leverage them effectively while ensuring that they continue to perform well over time. It offers capabilities in the areas of model lifecycle management, automated model deployment, model governance, and model monitoring. Specific capabilities of note include data drift and decay monitoring, update checking, and automated alerting mechanisms.
ClearScape Analytics provides connectivity plugins with Dataiku and H20.AI as well as API integration with AWS Sagemaker, Google Vertex AI, and AzureML.
Teradata has been the gold standard for data warehousing for several decades, offering extensive breadth and depth of analytical capability, and ClearScape Analytics both inherits and furthers that lineage. Moreover, while challengers have emerged, they have neither the breadth nor the depth that Teradata can offer. While machine learning support is increasingly common currency other vendors cannot typically compete with the capabilities offered by 4D Analytics, and rarely offer much in the way of ModelOps capabilities at all.
By bundling its analytics capabilities into ClearScape Analytics and allowing you to deploy it with any Vantage product, but especially with VantageCloud Enterprise or VantageCloud Lake, Teradata enables you to choose which kind of data architecture you want, what sort of querying you want to do, and what kind of analytics you want to use, essentially creating a modular analytics architecture. Moreover, ClearScape Analytics consistently provides benefits and drives positive business outcomes, regardless of your use of VantageCloud Enterprise or VantageCloud Lake.
The Bottom Line
ClearScape Analytics offers an exceptionally robust and well-proven set of analytics capabilities, including machine learning and ModelOps. In short, there is a lot to recommend it.
Mutable Award: Platinum 2023

Teradata Vantage
Last Updated: 19th November 2021
Mutable Award: Gold 2021
Teradata Vantage is a data warehousing and analytics solution that is effectively a merger between what was previously Teradata Database and Aster Analytics. It delivers advanced analytics while supporting machine learning and graph functions. Moreover, it makes it easy for analysts, data scientists, and line of business users alike to harness these functions to address business opportunities.
Deployment options for Teradata Vantage are varied, and include on-premises and cloud options (notably including hybrid cloud), but for the purposes of this report we focus on the latter, and thus explore Teradata Vantage as a cloud solution. As such, we have split our discussion into two parts: the first is a truncated discussion of the platform’s general functionality (see our prior InBrief on Teradata Vantage for the full discussion) while the second explores the product’s cloud capabilities specifically.
Customer Quotes
“A lot of cloud providers are saying they have [flexibility and scalability]. But what’s the real cost of the solution? What’s the price-performance and scalability? Can it handle complex workloads? We knew that Teradata can not only handle the simple 3-second queries, but also the complex queries with many joins without suffering in query response times.”
Brinker International
“Going to the cloud with Teradata Vantage on AWS, it was amazing to see what other vendors only touted. I can scale up, in double or triple the size, within minutes and have all the computing power separate from storage to do the big workloads. Then, scale back down to keep ongoing cost-effectiveness in place.”
Brinker International
Teradata supports a wide variety of languages for analytic purposes, most notably Python and R, as well as Jupyter Notebooks. It also offers an AnalyticOps Accelerator, a collection of best practices, proven design patterns, and tried-and-tested code derived from successful Teradata projects, that is designed to make it much easier for you to implement an AnalyticsOps framework.
The platform offers graph capability, support for machine learning, and access to “Advanced SQL”, Teradata’s extension to SQL in support of advanced analytics and machine learning at scale. This includes time-series and temporal functions that, along with comprehensive geo-spatial support, are combined in what Teradata calls “4D Analytics”.
Teradata also provides a wide range of industry and analytic models.
All of the capabilities described above are delivered in the cloud just as they are on-premises, allowing Teradata Vantage to be used as a highly effective cloud data analytics platform. It can be deployed across a number of clouds, including the “big three” of AWS, Microsoft Azure, and Google Cloud, as well as VMware, Teradata Cloud, and purpose-built on-premises infrastructure.
Multi-cloud, hybrid cloud, and hybrid multi-cloud are all supported, and in terms of the cloud the product is generally delivered as a service. Any number of instances can be viewed, managed and monitored using the same web interface, which is particularly important for multi-cloud. In addition, Teradata Vantage is a highly portable solution (including its licensing – see below), largely owing to the fact that it uses the same software across all platforms. Teradata also provides data migration tools and best practices, and combined with the company’s experience with cloud migrations, moving an instance from one cloud to another should be a relatively painless process.

Fig 01 - Teradata Vantage ‘Big 3’ cloud integrations
What’s more, the platform’s relationship with these clouds reaches significantly beyond just deployment.
In fact, Teradata Vantage is closely aligned with all three major clouds, and boasts integration with a wide variety of Microsoft, Amazon and Google cloud services, as shown in Figure 1. Moreover, Teradata Vantage offers a software architecture (see Figure 2) that is well suited to the cloud, which helps to take advantage of the aforementioned cloud services provided by Azure, AWS and GCP.
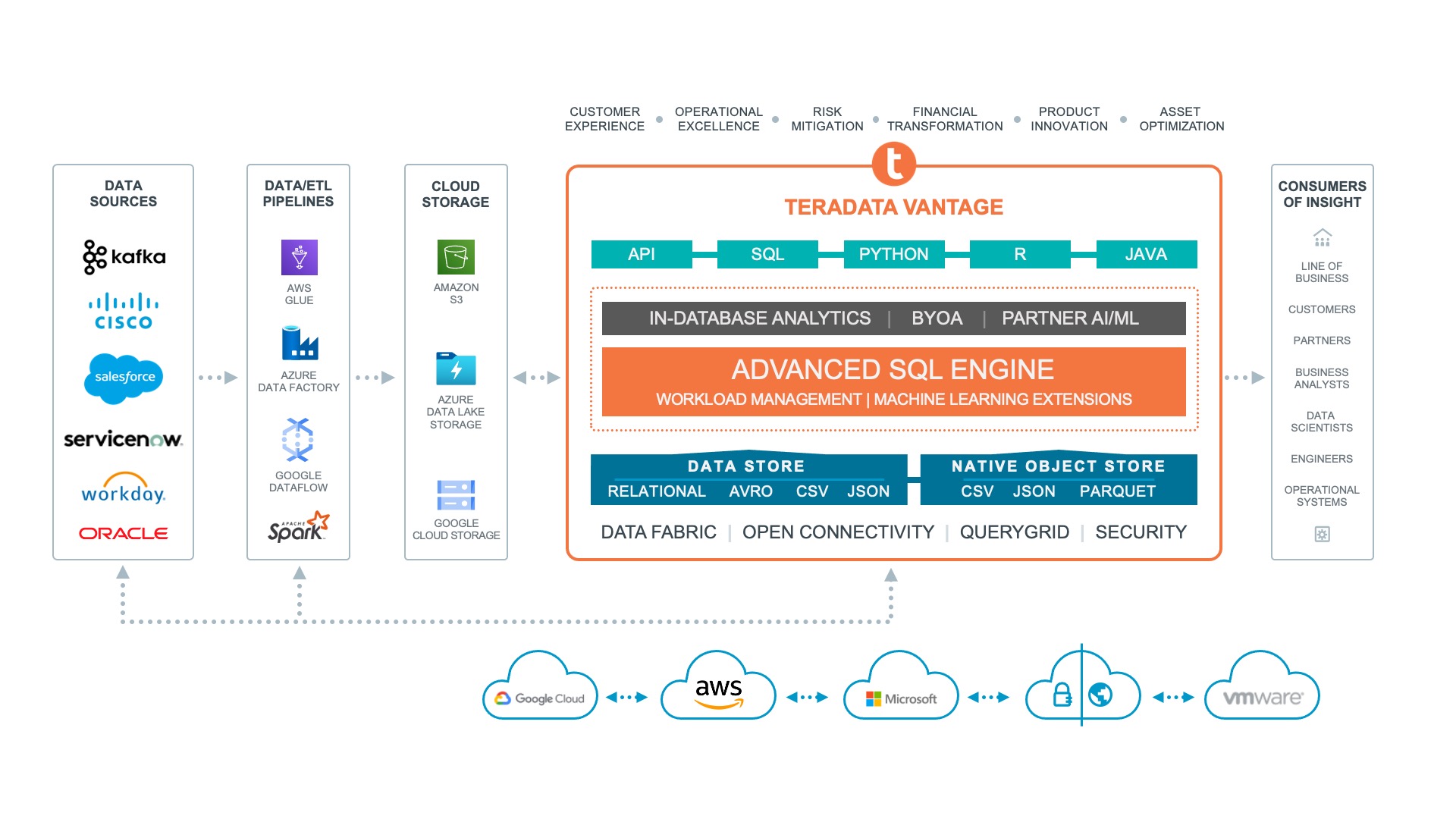
Fig 02 - Teradata Vantage cloud architecture
Pricing models for Teradata Vantage in the cloud are flexible, consisting of both capacity-based pricing (‘blended’) and pay-as-you-go usage-based pricing (‘consumption’). The latter, in particular, provides automatic elasticity, and you only pay for successful queries and loads. It also boasts highly trackable usage statistics (which makes for predictable pricing), and departmental chargeback, among other things. In short, you are able to choose whichever pricing model suits your needs, most likely in terms of high or low (or unknown) utilisation. Also notable is that all Teradata Vantage cloud deployments are single-tenant, which has benefits for both performance and stability, and that Teradata’s pricing models and licenses are portable across cloud (and even on-premises) environments.
Teradata Vantage also offers separation of storage from compute, which helps support these pricing models (particularly consumption pricing). That said, it is not strictly required. Elastic scaling, dynamic resource allocation, software performance optimisation (via indexing and determining least-cost execution methods), and workload management are all available, and all contribute to performance in one way or another. Dynamic resource allocation also addresses data replication and data drift, as well as query prioritisation more complex than ‘first come, first serve’.
Teradata has been the gold standard for data warehousing for several decades. While new challengers have emerged over the last few years, they have neither the breadth nor the depth that Teradata can offer. While machine learning support is increasingly common currency other vendors cannot typically compete with the capabilities offered by 4D Analytics. This will be particularly true within IoT (Internet of Things) environments but is by no means limited to those use cases.
As a cloud solution, Teradata admixes its signature, widely-regarded analytics with the benefits of the cloud. This most notably includes increased flexibility, scalability, and ease of use. Starting with a modest Teradata cloud deployment, paying only for what you use and scaling up precisely as much as you need to also removes much of the onboarding difficulties that often come with a solution as broad and fully-featured as Teradata, while at the same time reducing risk and hastening time to value.
The Bottom Line
Teradata Vantage is well-known for its performance, scalability, high availability and reliability. These qualities are retained, and in some cases enhanced, in cloud deployments. In short, with its strong history, proven use cases and exceptional capabilities, Teradata Vantage should be considered for any cloud and/or on-premises analytic database requirements.
Mutable Award: Gold 2021

Teradata VantageCloud Lake
Last Updated: 25th May 2023
Mutable Award: Platinum 2023

Fig 1 - Teradata VantageCloud architecture
Teradata Vantage is a connected, multi-cloud data platform for enterprise analytics that aims to provide a unified solution for all of your data sources. It delivers advanced analytics and machine learning functions, and makes it easy for analysts, data scientists, and line of business users alike to harness these functions to address business opportunities. Its core value proposition is that it will help you to operationalise your AI by improving the productivity of your data scientists, training your models at scale, and situating those models within a concrete business context that directly links them to business outcomes.
VantageCloud – formerly Vantage in the Cloud – is a version of Vantage that operates as a cloud analytics and data platform, offering the aforementioned capabilities as part of a cloud deployment. VantageCloud comes in two versions: VantageCloud Enterprise and VantageCloud Lake. VantageCloud Enterprise is similar to the previous Vantage in the Cloud offering, and accordingly is suitable for mixed, business-critical enterprise workloads. VantageCloud Lake, on the other hand, is a new development that has been designed to enable exploratory analysis and that can operate wherever your data already exists. Both Enterprise and Lake VantageCloud offerings can be used standalone or in conjunction with one another, and both are built on the same underlying tech stack (which is itself very similar to the stack used by on-premises Vantage deployments).
ClearScape Analytics refers to the analytic capabilities available as part of the Vantage platform, including VantageCloud and deployments thereof. It is comprised of more than 150 in-database functions, open and connected integrations/APIs, and features enabling the full-scale activation and operationalisation of analytics. In particular, this means that the same analytics functionality underpins all Vantage deployment options.
For this report we will be focusing on VantageCloud Lake, although we are also publishing a sister report that covers ClearScape Analytics.
Customer Quotes
“We are always looking to provide the best experience for Giants fans, which we can do by leveraging all of our data in the most efficient and insightful way. We look forward to working with Teradata’s VantageCloud Lake platform to help us enhance our analytics capabilities by accessing, connecting and making well-informed decisions through data.”
New York Giants
VantageCloud Lake is designed to let you run analytics on data in the object store and other systems while leveraging the push down capabilities of Teradata’s data fabric. This provides the ability to move the query to the data rather than incurring the costs and complexity of moving the data itself. It provides a self-service, web-based console for doing just that, as well as an open, connected analytics framework, enabling you to either leverage analytics capabilities provided by ClearScape Analytics or to bring your own. Third-party API support and integrations are also featured, and collaboration is supported via data sharing and the Teradata store.
VantageCloud Lake uses a new, consumption-based pricing model that offers optimised, unit-based pricing. It also offers a variety of spend management features. For instance, it provides automatic elasticity with incremental, intelligent scaling, meaning that you only scale up when your currently allocated resources reach their limits, and you only pay for the amount of data actually accessed or stored rather than just provisioned. The product boasts highly trackable and comprehensive usage reporting, which makes for predictable pricing and holistic financial visibility, and you can put guardrail policies in place on particular workloads to prevent accidental overspending. In addition, VantageCloud Lake separates storage from compute, which helps support this pricing model by enabling granular chargebacks to compute cluster owners. Multi-cluster compute is available.
The product also features several built-in resiliency features, such as backup-as-a-service, and rolling upgrades delivered via CI/CD pipeline. High availability is provided, and is enhanced via the session manager, which will hold user sessions and queries in place even if the application they are using goes down.
At present, VantageCloud Lake is available on AWS and Azure, with Google Cloud integration planned for 2024.
Teradata has been the gold standard for data warehousing for several decades, offering extensive breadth and depth of capability, but with VantageCloud Lake it has have taken a step forward to bring its well-developed analytics capabilities to wherever your data lives.
This provides considerable benefits to ad hoc and exploratory querying, which by their nature require low up-front costs in terms of time and effort expended by the user in order to be efficient. Essentially, having to move your data (and quite likely a lot of it to, since the whole point of exploratory testing is that you do not know precisely what you are looking for) to a data warehouse in order to perform a one-off query on it is a lot of wasted effort, and in such a scenario we would imagine that exploratory and ad hoc queries just do not happen, or if they do are a laborious process that everyone would rather avoid doing. VantageCloud Lake provides alternatives by allowing you to move your data to low-cost storage (such as the object store) and by enabling you to move your query rather than your data.
Past that, VantageCloud Lake possess many of the same strengths and capabilities as Vantage in the Cloud before it, but is now deployed in a much more cloud-focused architecture. As such, it benefits from Teradata’s considerable analytics capabilities as well as enjoying all of the advantages of the cloud, including flexibility, scalability, and ease of use.
The Bottom Line
Teradata VantageCloud Lake is by no means a complete replacement for more traditional enterprise analytics (at least, not yet), as seen in, say, VantageCloud Enterprise, but it is certainly a compelling complement to it. At the same time, it – and VantageCloud in general – has retained many of the qualities that have made Teradata Vantage so well-regarded in terms of performance, scalability, high availability, reliability, and so on. In short, it is well worth considering for inclusion in your analytics suite.
Mutable Award: Platinum 2023

The Fabric of Teradata
Last Updated: 2nd April 2024
Mutable Award: Gold 2024

Fig 01 - Overview of Teradata VantageCloud
A data fabric architecture, at heart, is about providing a unified view of a corporation’s data assets without having to necessarily move copies of data from source systems into a dedicated query environment, such as a data warehouse or a data lake. Teradata clearly has a long history in the data warehouse world, but has added several capabilities to allow it to operate within the data fabric architecture. Teradata’s QueryGrid feature provides a window into multiple data sources, whether they be on-premises or in a private or public clouds. It provides data virtualisation, showing a unified view of data across multiple sources.
Crucially, QueryGrid provides for distributed query processing, a vital element of a data fabric and one which is conveniently overlooked by many vendors claiming to operate in the data fabric space. A query can be constructed by accessing data from Teradata Vantage itself and Hadoop files, object stores and other data sources, whether on-premises or cloud. There is an optimiser and management system that prioritises and balances workloads and provisions resources like processors and memory to efficiently execute complex queries. Access controls and data policies can be applied, including data masking and encryption where needed. Teradata Vantage executes a query in the most efficient manner, pushing down query processing close to the data gravity versus moving the entire data sets. It has connectors to Hive, Starburst, Oracle, Spark and Google Big Query amongst others. There is also a natural language interface, currently in private preview, named ask.ai, enabling users to pose queries in plain English, which then generates the required access statements in the underlying systems, such as SQL statements for relational databases.
Customer Quotes
“With Vantage, enterprise-scale companies like Target can eliminate silos and cost-effectively query all their data, all the time, regardless of where the data resides.”
Samantha McIntyre, General Manager of Technology, Target
“To be focused on a consumer, all the behaviors and actions must be ingested and then integrated to use it in an analytical way, Teradata VantageCloud on Google Cloud is the platform that helps us to integrate all this information together and to build a customer view.”
Ignacio Charfole, Head of Big Data Architecture & Governance, Telefonica
“Teradata’s products are superior to the competition because of their strength on the front-end as an access platform and their user experience. You don’t have to be a data expert to access and use data.”
Kazutoshi Ono, CTO/CIO, Credit Saison group

Fig 02 - Integrate data without moving or duplicating it
Teradata’s QueryGrid feature allows a virtual window into data, wherever it may be sourced, and presents this data to end users. Semantic mapping enables data to be presented in a user-friendly format, eliminating the need for users to be familiar with the underlying physical structures. This layer goes as far as handling deduplication of data and consolidation of data sources where appropriate.
Teradata has a partnership with Microsoft, and this includes working with the Microsoft Data Fabric product set. Teradata’s AI Unlimited, currently in private preview, will work with the OneLake logical data lake within the Microsoft Fabric environment. However, Teradata’s Data Fabric offering can expand the reach of Microsoft Fabric to non-Fabric data sources; it is offered as an option alongside, aimed at customers who have already committed to the Microsoft product.
Teradata Vantage allows customers to construct an analytics environment without necessarily copying data from sources into a separate data warehouse: this is the goal of a data fabric. In practice, this approach has some limitations in specific instances where there are performance SLAs, where it could be better if the data is localized and tuned in the processing engine of choice. In reality, some data will be more naturally materialised and re-used in queries. However, Teradata Vantage makes this approach transparent to the end user and allows each customer to be as virtual or otherwise as they wish to be in the way they set things up.
The recent interest in data fabric has caused a lot of vendors to frantically re-label what they had before as data fabric-friendly. However, some things are much harder than others to build. Producing a knowledge graph from a catalog is one thing, but building a proper distributed query engine with an effective optimiser is a much more complex task. Teradata is fortunate in that they have long had the foundations for this, based on their heritage in high-end data warehousing.
They have a well-proven semantic layer, a catalog, a knowledge graph, good source data integration and above all a proper distributed query optimiser, so the key elements of this architecture are all in place. Many data fabric solutions require stitching together several elements from different vendors or open-source solutions. Teradata is about as close as you will find to a complete offering in the data fabric world.
The bottom line
Teradata has built on its long heritage in highly scalable data warehousing and have extended this deftly into the data fabric world. Moreover, they have many customers actually using this approach in practice. For a proven data fabric solution versus something shown via PowerPoint or a canned demo, Teradata should be high on your list to consider.
Mutable Award: Gold 2024

Commentary
Research

Data Fabric

The Fabric of Teradata

Teradata ClearScape Analytics

Teradata VantageCloud Lake

Options for analytic databases and data warehouses (2023)

Options for analytic databases and data warehouses (2022)

Teradata Vantage (2021)
