
Enov8
Last Updated:
Analyst Coverage: Daniel Howard and David Norfolk
Enov8 is an Australian software vendor specializing in IT environment management solutions that support non-production and production environments for DevOps, testing, and software delivery. Originally founded in 2013 as a spin-off from an IT services company, Enov8 has built a strong reputation for supporting automation and best practices that enhance IT operations. The company primarily services large enterprises across financial services, government, telecommunications, and other highly regulated industries. It operates across most geographies and industries.
Enov8 is also the creator of the Environment Management Maturity Index (EMMi), a strategic framework designed to help organizations systematically improve their development, test and production environment management practices.
Enov8 Test Data Manager
Last Updated: 5th March 2025

Fig 1 - Enov8 product architecture
As shown in Figure 1, Test Data Manager sits on top of the core Enov8 Application Portfolio Management layer, alongside Release Manager and Environment Manager. As its name implies, it is designed to help you manage your test data, addressing common issues like test data bottlenecks, privacy, and so on. It accomplishes this by using automation to simplify, systematise and accelerate your test data management processes, such as data profiling and data masking. This automation comes in various forms, some of which optionally leverage AI and machine learning in the background.
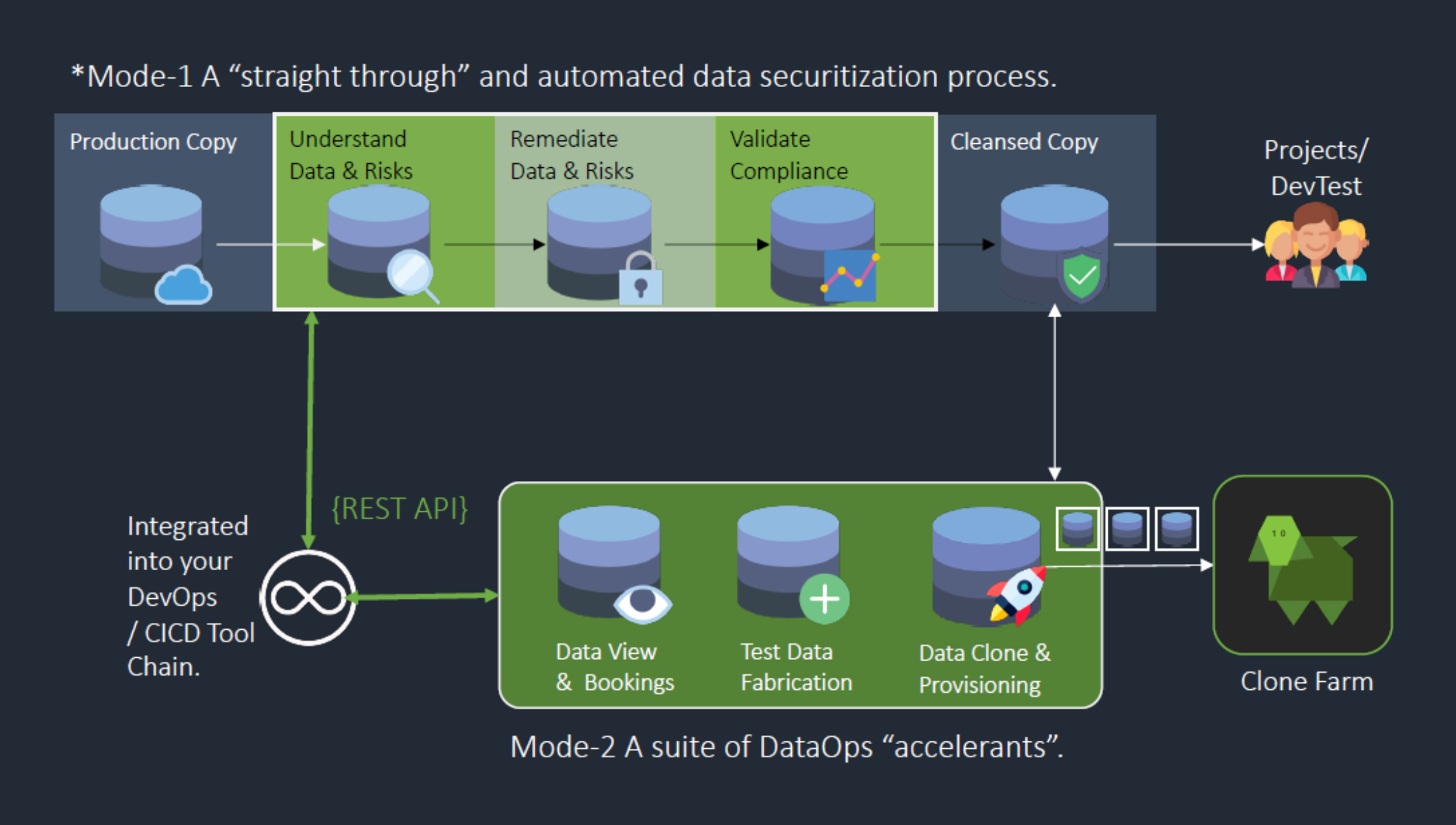
Fig 2 - Mode-1 and Mode-2 TDM operations
Test Data Manager offers solutions for two major aspects of test data management. The first of these aspects is data security and regulatory compliance, delivered via automated data profiling, data anonymisation, and compliance validation. The second is test data agility and DataOps acceleration, provided via synthetic data generation, test database orchestration (of either traditional test databases or virtualised database clones), and test data provisioning. Enov8 refers to these two aspects as “Mode-1” and “Mode-2”, respectively, and they can be implemented either individually or (more likely) simultaneously (see Figure 2).
In particular, the database virtualisation capabilities offered as part of this process are derived from integration with Enov8’s VirtualizeMe (vME) product, which allows you to rapidly deliver extremely lightweight database clones to your development and testing teams for test data management (by creating virtualised test data sets) and other purposes. This capability is sufficiently advanced that it is worth covering separately, and we have done so here. Test Data Manager functionality can also be delivered through an API, perhaps integrated into an existing DevOps process or CI/CD toolchain, as shown in Figure 2. It can operate across domains, including cloud and on-premises environments, in a federated (and load balancing) fashion, via a network of “worker bees” (agents) that report to the core platform. This provides a significant degree of parallelisation and scalability. In terms of data sources, Test Data Manager supports a variety of the most popular relational and NoSQL databases, various kinds of text files (including CSV, JSON, XML, and fixed width), and a smattering of other formats, such as Avro, ORC, and Parquet.
Customer Quotes
“Enov8 Test Data Manager ensures secure, compliant test data with easy risk profiling, masking, validation, and streamlined provisioning. Enabling us to marry TDM and DataOps.”
Global Insurance Provider
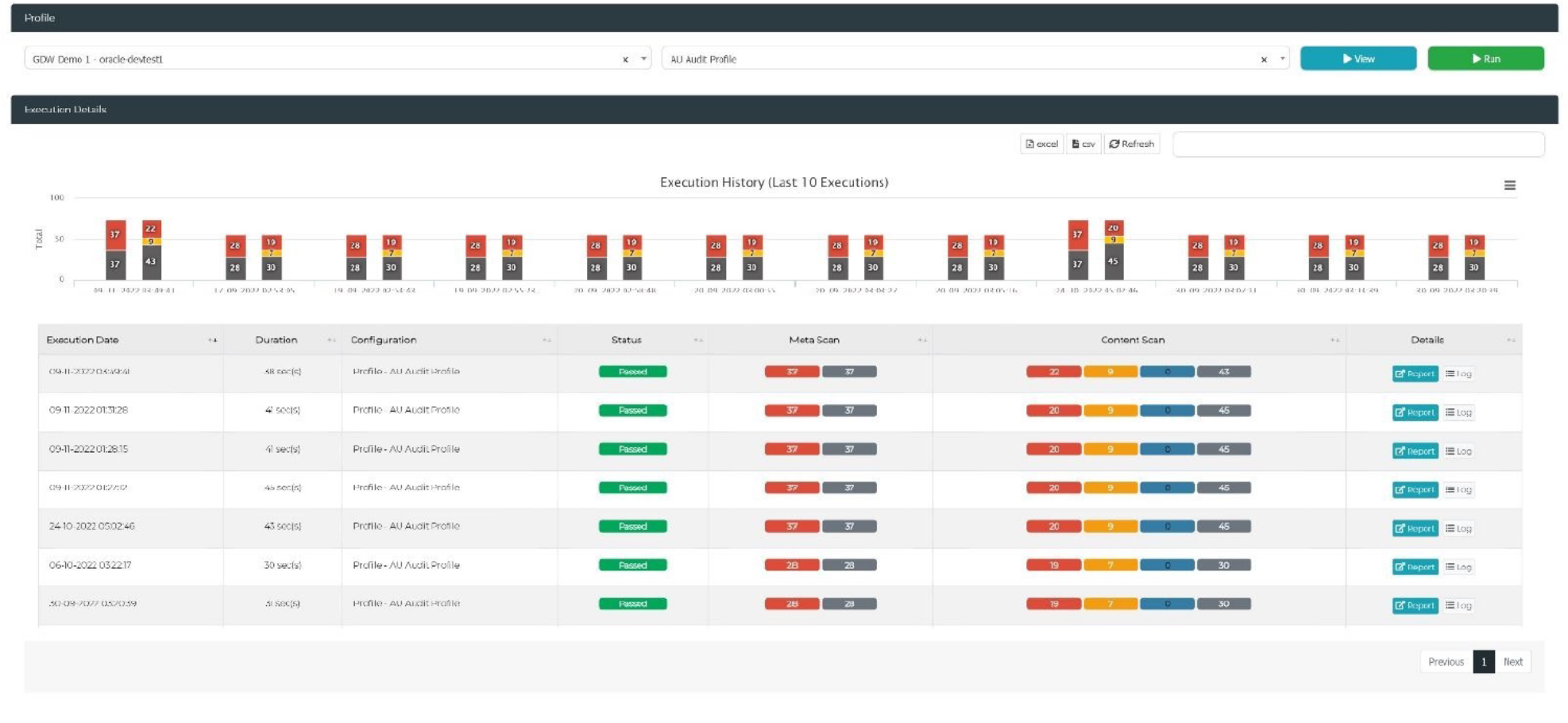
Fig 3 - Test Data Manager profiling execution report
Data profiling in Test Data Manager (for finding your sensitive data, among other things) consists of creating and running data profiling configurations that specify the selection of data fields, and corresponding data patterns, you want to identify. You can flag fields as sensitive within these configurations, and even specify what kind of sensitivity (such as primary PII, secondary PII, or PHI) each field falls under. In addition, various preset profiling patterns and configurations are available, catering to common, international use cases. Data fields are identified using column name and/or pattern matching, and the results of data profiling are presented within profiling reports available for each profiling job individually and for all of them collectively (see Figure 3 for an example of the latter).
Profiling configurations can also contain recommended data masking (or other anonymisation) methods for each (sensitive) field. During the anonymisation process, you can either rely on these preconfigured methods or choose your own. Enov8 generally recommends using a hashing algorithm to replace sensitive values with random ones drawn from a pre-generated many-to-one lookup table. This method is flexible, non-reversible, maintains referential integrity and can produce production-like data. A selection of look-up tables for common fields are provided out of the box to facilitate this. The product also uses essentially the same method to create synthetic data sets, except that instead of anonymising a series of existing fields it simply creates a set number of them.
Other anonymisation methods are also available, and include encryption, complex ciphering, random or fixed variance (for numerical fields) and fixed value replacement (which is to say, everything is masked to the same thing). You can also implement your own masking algorithms as Python functions, with templates for the above methods provided. Similarly, you can use Python to extend or modify any of the built-in masking methods. You can also use parameters to perform calculations and leverage their results during the masking process, such as when calculating a checksum or masking a field that needs a concatenation of other masked fields.

Fig 4 - Test Data Manager executive insights dashboard
Masking can be executed manually or scheduled as part of the company’s Orchestration Manager (and in fact can be positioned as part of an automated pipeline, along with profiling and various other tasks, using the same). The masking process can be paused and resumed intelligently, so that existing progress is not lost, and ultimately produces a report detailing which masking jobs succeeded and which (if any) failed. In the latter case, error details are provided, and you can choose to rerun only the failed jobs once those errors have been fixed. Delta analysis is available for change management purposes where an update to the database schema may have introduced new fields, and masking validation available as part of the report will tell you both how production-like each field’s masked data is (using distribution analysis) and what percentage of values have been masked within each field.
Finally, for Test Data Mining, Test Data Manager offers a data library that allows you to both view and reserve data. Various data dashboards are also available (an example of which is shown in Figure 4) that can be customised both for your organisation as a whole and by each user individually.
Test Data Manager provides considerable breadth of test data management functionality. To wit, it offers a complete test data solution, providing sensitive data discovery (via data profiling), data anonymisation (via masking), and database virtualisation (when used alongside vME, which is highly recommended). It also benefits from being part of a product suite alongside Enov8’s other offerings, such as Environment Manager, Release Manager, and Orchestration Manager. In short, it allows you to protect your sensitive test data – and comply with any relevant regulations – while accelerating your test data processes and ensuring they do not become a bottleneck for your testing as a whole. Synthetic data generation is also available, although in this case we would say it is best considered as an ancillary capability for complimenting your other test data with new data that may not exist in production.
Using distribution analysis to determine how closely your masked data resembles your production data is a rarely seen, but welcome, feature. It allows you to create test data sets that are highly secure but retain the statistical properties of the original data, enabling you to test as if you were using the original data but without the accompanying privacy concerns. The selection of masking and matching methods provided by Test Data Manager are relatively minimal, but its primary method of masking – using many-to-one lookup tables – compensates for this through sheer flexibility, and you can add to the available masking methods yourself if required.
It is also worth noting that Test Data Manager is quite easy to use through its web interface, to the extent that, at least in principle, it can be leveraged by both technical and non-technical users. At minimum, this makes your testers’ lives easier. More significantly, this can allow parts of your organisation outside of your dedicated testers to assume some responsibility for test data, helping you to spread the load and utilise tribal knowledge. In theory, you could even federate out your test data management entirely, with your dedicated testers primarily acting in a test data governance capacity.
The bottom line
Enov8 Test Data Manager is a robust solution for data profiling and data masking, with additional capabilities for test data provisioning and synthetic data generation (among other things). When combined with vME, the database virtualisation offering also from Enov8, it offers a holistic and comprehensive solution for test data management, ensuring test data security, compliance, and efficiency, especially within DevOps environments.
Enov8 VirtualizeMe
Last Updated: 25th November 2024
Enov8 VirtualizeMe (“vME”) is a database virtualisation solution, meaning that it allows you to rapidly deliver extremely lightweight database clones to your development and testing teams. These clones can be created and destroyed at will, and have a very small storage footprint. Due to these features, personalised instances of each clone can be distributed to any and all of the relevant users. vME can be deployed on-premises or in the cloud, and is currently available on the AWS Marketplace.
The primary (though not the only) use for database virtualisation, and vME by extension, is test data management: by testing with entire, virtualised databases, you ensure that the range of data you are testing with is comprehensive while maintaining test speed, in turn preventing test data from becoming a bottleneck to your wider testing and development processes. vME in particular is well-suited to creating virtualised test data sets, and is capable of both centrally managing and accelerating your test data operations while reducing wait times and minimising disk storage.
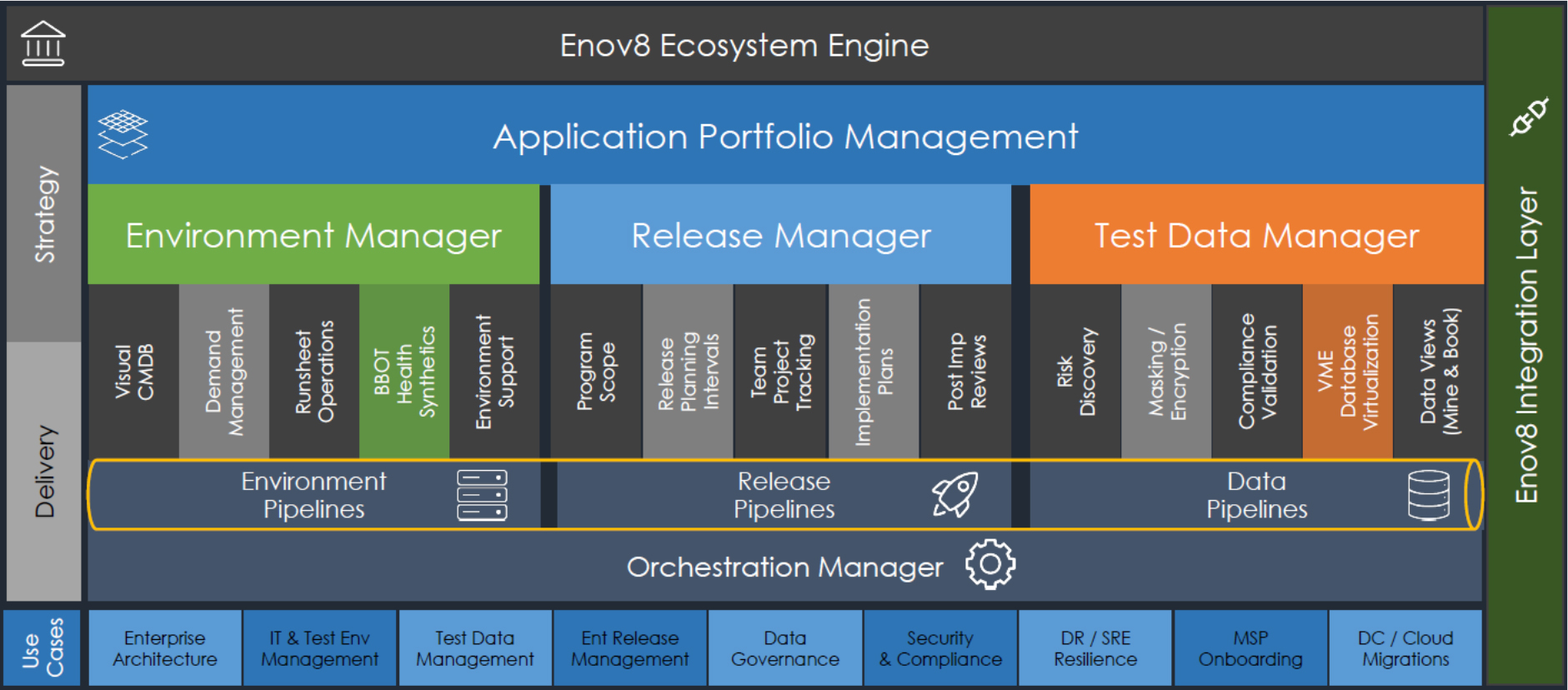
Figure 1 – vME’s position in the Enov8 architecture
There is one aspect of test data management that vME does not cover: the discovery and masking of sensitive data, which you will need in order to prevent unprotected personal (or otherwise sensitive) data from entering your test environments. This is intentional, as this functionality is instead provided by vME’s sister product, Enov8 Test Data Manager, which can integrate with vME in order to do so (see Figure 1). That said, Test Data Manager is not strictly required to access this functionality. In fact, vME can also be deployed alongside third-party test data management solutions, enabling you to leverage their discovery and masking capabilities alongside vME’s database virtualisation.
Customer Quotes
“Enov8 supercharged our test data provisioning, turning a once complex and time-consuming process into an effortless, on-demand service. It’s a game-changer for speed and compliance.”
Major Australian Bank
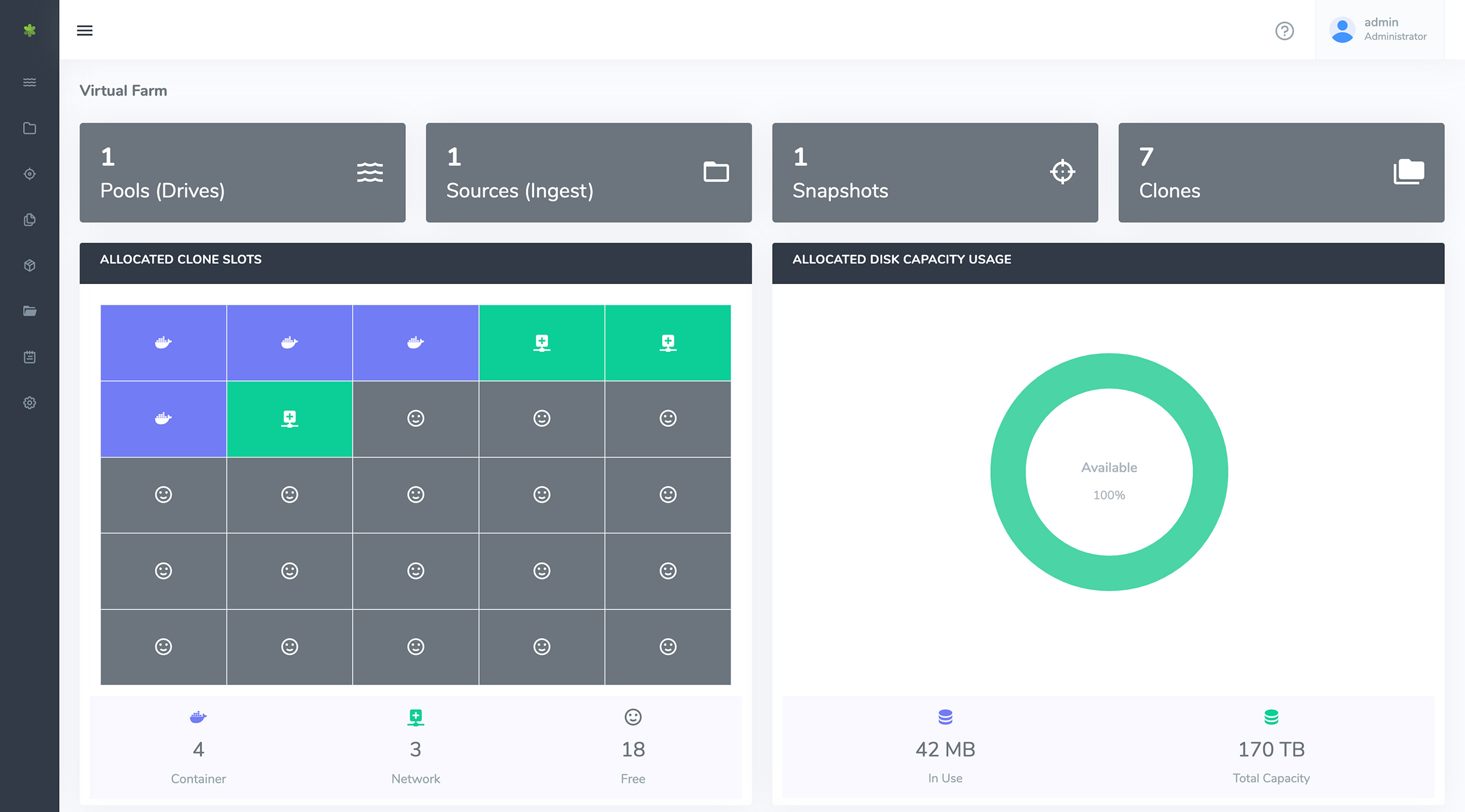
Figure 2 – vME web interface
vME provides a dashboard user interface (shown in Figure 2) for controlling four kinds of virtualised data assets: pools, sources, snapshots, and clones. These are hierarchical: sources are derived from pools, snapshots from sources, and clones from snapshots. The process starts by ingesting a backup file for the database from which you wish to create these assets, and this can be actioned within the dashboard, as can the distribution of clones to your users.
Pools are collections of virtual storage devices that have been grouped together, and are standard technology for ZFS, the underlying system on which vME is built. Sources are essentially ingestion points for a given pool, and are usually containerised when the type of database you are working with permits it. Snapshots are point-in-time bookmarks for a given source, while clones are virtual copies of the source at that point in time. The reason clones are so small is that they only store differences between them and the snapshot from which they were created, which will initially be nothing and is unlikely to grow that much due to their distributed and often temporary nature. Clones can be either container or network mounted, and can themselves be bookmarked (effectively creating different versions of the same clone, which can then be reverted to at a later date).
Data discovery and masking is typically actioned at the source level, before a snapshot is taken, whether through Test Data Manager or a third-party product. The effects of these processes are then carried forward, meaning that you only need to find and protect the sensitive data in a given source once (at least until the source is updated) and the sensitive data in every clone created from that source will also be protected.
vME is designed to be DevOps-first. Accordingly, its functionality can be accessed via APIs or a CLI (Command Line Interface) in addition to the web interface already described. This allows it to fit neatly into existing workflows and toolchains, particularly CI/CD pipelines. The web interface also provides a file explorer for examining and manipulating containerised data. Moreover, vME’s underlying engine interacts with data at the file system block level, which means that vME is both database and file type agnostic. It also uses a federated approach, promoting a load-balanced architecture and allowing you to distribute vME application instances to teams or individuals as needed.
Finally, vME recently added the ability to leverage IBM ZD&T (the IBM Z Development and Test Environment) to create clones of z/OS mainframes. This is useful from a testing standpoint, but also for training purposes: by distributing mainframe clones, you can provide sandboxed environments to trainee mainframe users. This is helpful because there is a significant shortage of mainframe developers, and because it is normally quite difficult to give prospective developers a mainframe environment to safely play in. By addressing the latter, vME can help to address the former as well.
Database virtualisation is still an emerging technology in test data management, but its efficacy and desirability have been clear for some time. One of its major issues has been cost, with one of the most prominent virtualisation vendors exclusively targeting only the wealthiest companies, and setting its prices accordingly. This has meant that database virtualisation has, historically, been largely out of reach of both small and medium-sized enterprises. vME is one of a new breed of database virtualisation products that is available at a price point that is affordable for these vendors.
Indeed, vME’s affordable price point, easy deployment, and self-service approach give it a pleasingly short time to value. In particular, this makes it an excellent candidate for deploying to specific teams, tribes, or even individual users within an organisation, either on a permanent basis or as part of a gradual, enterprise-wide rollout. Moreover, its integration with third-party tools and DevOps-compatible design means that it will fit cleanly into many existing test environments and toolchains. Its ability to help train mainframe developers by providing z/OS clones is also notable.
The bottom line
Enov8 VirtualizeMe is a capable and compact database virtualisation solution that is oriented towards test data management. In that respect, it caters to a wide variety of enterprises and environments, whether in combination with Enov8 Test Data Manager or by integrating with existing test data management tooling. If you do not already have access to database virtualisation (and perhaps even if you do) you should seriously consider adding VirtualizeMe to your testing environment.

Environment Management
Last Updated: 1st April 2025
Mutable Award: One to Watch 2025
Modern enterprises struggle with fragmented IT environments, slow-release processes, and inefficient test data management. Without a unified approach, organizations face higher costs, compliance risks, and delivery inefficiencies.
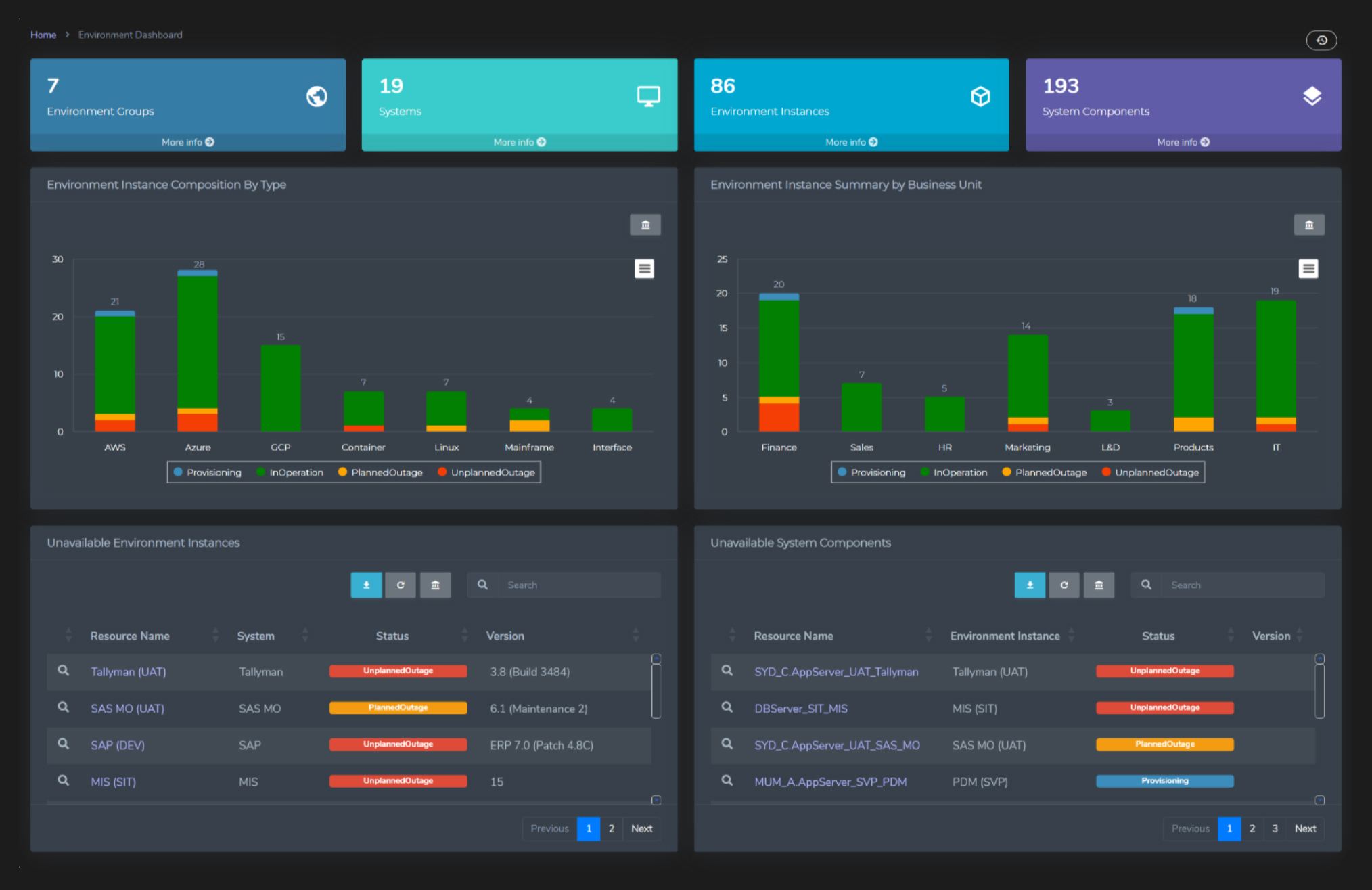
Fig 1 - Enov8 Environment Manager, the user interface
Enov8’s Environment Management solution is a key component of its broader IT management platform, with an attractive visual interface (see Figure 1), which also includes Application Portfolio Management, Release Management, and Test Data Management. This forms a complete, proprietary ecosystem with good connectivity to other products, which has real advantages for completeness of coverage – it can support tracking and protection of PII (Personally Identifiable Information), for example, across all of your non-production environments. It might appear more complex than other solutions until you understand its approach and underlying philosophy but, fortunately, Enov8 has good support services and the EMMi, that help you manage continual improvement in the use of the tool. You can start small, simply understanding what you are doing now, and increase the sophistication of your management of your environments as your experience with Enov8 Environment Management grows.
Enov8 Environment Management helps you to:
- Know what environments you have and why you have them.
- Maintain a plan which co-ordinates activities relating to your environments.
- Manage demand and contention for environments.
- Manage and control changes to your environments and track incidents.
- Standardize good practice for operations relating to your environments.
- Implement automated operations as code wherever possible and integrate them with DevOps delivery pipelines.
- Maintain formal deployment and implementation plans.
- Implement real-time analytics, giving you insights into value-stream delivery.
This makes the whole Enov8 ecosystem into a somewhat specialized Configuration Management system (it has a CMDB, Configuration Management Database, for example) which ensures the completeness and integrity of the environments you use for testing. This implies a degree of necessary complexity, but each of the 8 areas listed above are supported out-of-the-box; seamless integration with tools and pipelines you already have is available; and, as we’ve said, comprehensive Enov8 support is offered.
The Enov8 Maturity Model is a structured framework which tracks operational maturity across 8 Key Performance Areas (KPAs) relating to Transparency, Release and Governance:
- Environment Knowledge Management – Understanding IT environments throughout their life cycle, including development, testing, training, and production phases.
- Environment Demand Awareness – Recognizing and managing the needs of environment consumers, such as project and DevTest teams, to ensure optimal resource utilization.
- Environment Planning & Coordination – Proactively organizing environment events and deployments to ensure systems are timely, properly configured, and fit for purpose.
- Environment IT Service Management – Implementing customer-focused IT service delivery and support, including the management of incidents, changes, and releases.
- Application Release Operations – Establishing consistent, repeatable, and traceable application release processes that contribute to effective IT environment management and delivery.
- Data Release & Privacy Operations – Ensuring that data release processes comply with privacy regulations and protect sensitive information.
- Infrastructure & Cloud Release Operations – Managing the deployment and maintenance of infrastructure and cloud resources to support environment needs.
- Status Accounting & Reporting – Maintaining accurate records and reports on environment status to support transparency and informed decision-making.
This should provide a framework for the supply of training beyond just the operation of the tools and should be an excellent basis for managing continual improvement. This does imply, however, that someone in the organization is thinking about the bigger picture – why are you using Enov8 and what will success look like. Enov8 delivers many benefits, but you won’t get them automatically, you will have to put some thought into how you use the tools.
Enov8 Environment Management gives you control of the many environments needed to operate and maintain business automation. Most commonly, these will be test environments – an accurate image of the production environment, usually at a smaller scale, in which you can test new code. Obviously, it is important to be able to set these up efficiently – and, also, to tear them down, in order to release resources. But you also need confidence in them being an accurate copy of production, scaled down, and you’ll need to be able to recreate exactly the same environment whenever you need to.

Fig 2 - Enov8 Environment Manager, the architectural context
Other environments you might need include ones for quality management, for integration testing, for performance management and so on. Enov8 Environment Manager is an integral part of a software platform (see Figure 2, Enov8 Environment Management, the architectural context) that manages Environments, Releases and Test Data. Enov8 Environment Manager’s key capabilities include:
- End-to-end environment management – it provides centralized SDLC (System Development Lifecycle) CMDB and visualization tools, to ensure clear documentation, modeling, and streamlined management of complex environments.
- Architectural blueprinting – it provides system deployment and IT service diagrams to visualize and understand infrastructure, dependencies, and configurations.
- Operations and demand management – it aligns environment availability with business needs, thus reducing bottlenecks and optimizing resource allocation.
- Booking and contention management – it has intelligent scheduling tools, which allow teams to reserve test environments, preventing conflicts and ensuring efficient resource usage.
- Service support and ITSM (IT Service Management) integration – it facilitates centralized management of changes, incidents, and support requests for better operational control and ITSM integration.
- BBOT Health Synthetics – which is a no-code monitoring solution that proactively detects issues across IT environments, improving reliability and reducing test failures (the name derives from worker Bees and automation roBots).
- DevOps orchestration – it automates environment provisioning, health checks, and decommissioning using orchestrated workflows and runbooks.
- Deployment tracking and release visibility – it tracks software versions across environments, ensuring accurate testing and reducing environment drift.
- Test data management – this helps to ensures compliance through data profiling, masking, synthetic data generation, and provisioning, thus allowing secure and efficient test execution.
- Enterprise release management – it provides structured governance for software releases within SAFe (Scaled Agile Framework) and other enterprise frameworks.
- Financial insights and cost optimization – this identifies cost-saving opportunities related to IT over-provisioning, idle resources, and inefficient environment use.
- Being platform and architecture agnostic – Enov8 Environment Management works across any infrastructure, cloud provider, programming language, or platform architecture.
An example is the best way to clarify what Enov8 Environment Management can do overall. Imagine an organization with some 250 people engaged in development testing, 200 environment instances and a Project Budget of $50M pa (per annum). Licensing Enov8 for 200 instances currently costs you US$96k pa (although you also need to consider implementation and training overheads, of course, so the simplified calculation given here is a bit optimistic).
- Enov8 Environment Management helps you to to reduce your footprint. Enov8 analysts estimate that in an un-managed situation you will likely over-provision environments by 20%. If each environment instance costs you about US$75k pa and you save 40 out of 200 environment instances, this is a potential saving of about US$3M pa. Obviously, part of implementing Enov8 Environment Manager is estimating the cost of an environment, and the other costs mentioned below, for your particular organization, so you can document actual cost savings.
- Enov8 Environment Management also increases the productivity of your development testing operation. Enov8 estimates lost productivity at about 5% in an un-managed system. If you employ 250 people for testing at an estimated US$80K pa per person (remember that people cost more than just their salaries), this gives you a potential saving of about US$1M pa.
- Finally, Enov8 Environment Management promises to streamline delivery. If you currently experience delivery delays through operational inefficiencies corresponding to some 2.5% of a US$50M budget, there is another US$1,25M potential saving.
This all adds up to a potential saving of US$5.25M pa for spending US$96k pa on Enov8 licenses. This seems reasonable to us, but only if you operate environment management as a sufficiently mature organization (one that actually achieves any potential payback), so Enov8’s training and consultancy services are important, as is continual improvement against, say, the Enov8 Maturity Model. There is an article offering assistance with ROI (Return on Investment) assessment here.
You should care about the Enov8 Environment Management platform because a failure to manage environments effectively is a major cause of, at best, wasted time and resources and, at worst, of poor quality software that fails in production. You may over-provision environments so as to be sure that one is available when needed. You may be maintaining development environments for legacy systems, for the current status quo, for your next major release and even, sometimes, temporary environments relating to a contingency. Managing all of these manually is time-consuming and error-prone and if you do use the wrong environment for, say, testing or integration, the results can be catastrophic.
You should also care about the availability of the Environment Management Maturity Index (EMMi) because managing environments is a journey, not an absolute. So, you can start small, using the Enov8 Environment Management software platform to manage those aspects of your environments that are giving you immediate issues and then track progress as you mature in each of the core dimensions of the EMMi. This is more achievable and less risky than a “big bang” approach.
The bottom line
The Enov8 Environment Management software platform allows you to manage IT development environments in a holistic and repeatable way, so as to minimize waste. It helps to ensure that the behavior of each of your automated systems is always predictable. By providing advanced visualization capabilities, Enov8 Environment Management ensures clarity and control over even the most complex IT landscapes. Ultimately, it helps you to do more with less, without any nasty surprises.
Mutable Award: One to Watch 2025

Commentary
Coming soon.
Research

Environment Management with Enov8

Enov8 Test Data Manager
