
IRI Data Integration
Published:
Content Copyright © 2024 Bloor. All Rights Reserved.
Also posted on: Bloor blogs

As I’ve discussed previously, IRI provides a robust solution for data migration. For those needing a recap, IRI is a longstanding data management vendor that has been almost perennially involved in data modernisation efforts (such as legacy “lift and shift” work). The company got its start facilitating mainframe sort migrations in the late 1970s, so it has a long and storied history in the sciences of data movement, manipulation, and modernisation, including data type and file format conversions as well as ETL operations through its widely adopted CoSort data transformation utility. This means that, in a similar vein to data migration, it also offers significant data integration functionality.
As another form of data movement, this is, perhaps, to be expected – although the nuances are different, many of the core challenges are similar. IRI offers its Voracity data management platform for graphical, end-to-end data integration powered by CoSort, as well as callable component pieces from outside the IRI platform itself. This latter option allows you to take advantage of IRI’s positive qualities – such as its time-tested performance – without needing to replace your existing solution. Indeed, increasing performance at a relatively affordable price point is one of IRI’s chief selling points when it comes to data integration.
In terms of data integration throughput acceleration, IRI offers fast extraction and loading tools, supporting the ‘E’ and ‘L’ parts of ETL. But the meat of the offering is in the speed and consolidation of its transformation capabilities. For instance, IRI’s extensive data masking, data quality, and data governance functionality (which, again, I’ve talked about before – see here, here and here) can be applied directly as part of the ETL process. Other functionality, such as data wrangling and business intelligence (which is to say, the production of intelligence reports) are also available during ETL. Moreover, the CoSort engine allows you to apply all of these transformations (in fact, any number and kind of transformations) to any number of targets in a single I/O pass, consolidating all of your transforms into a single, efficient step.
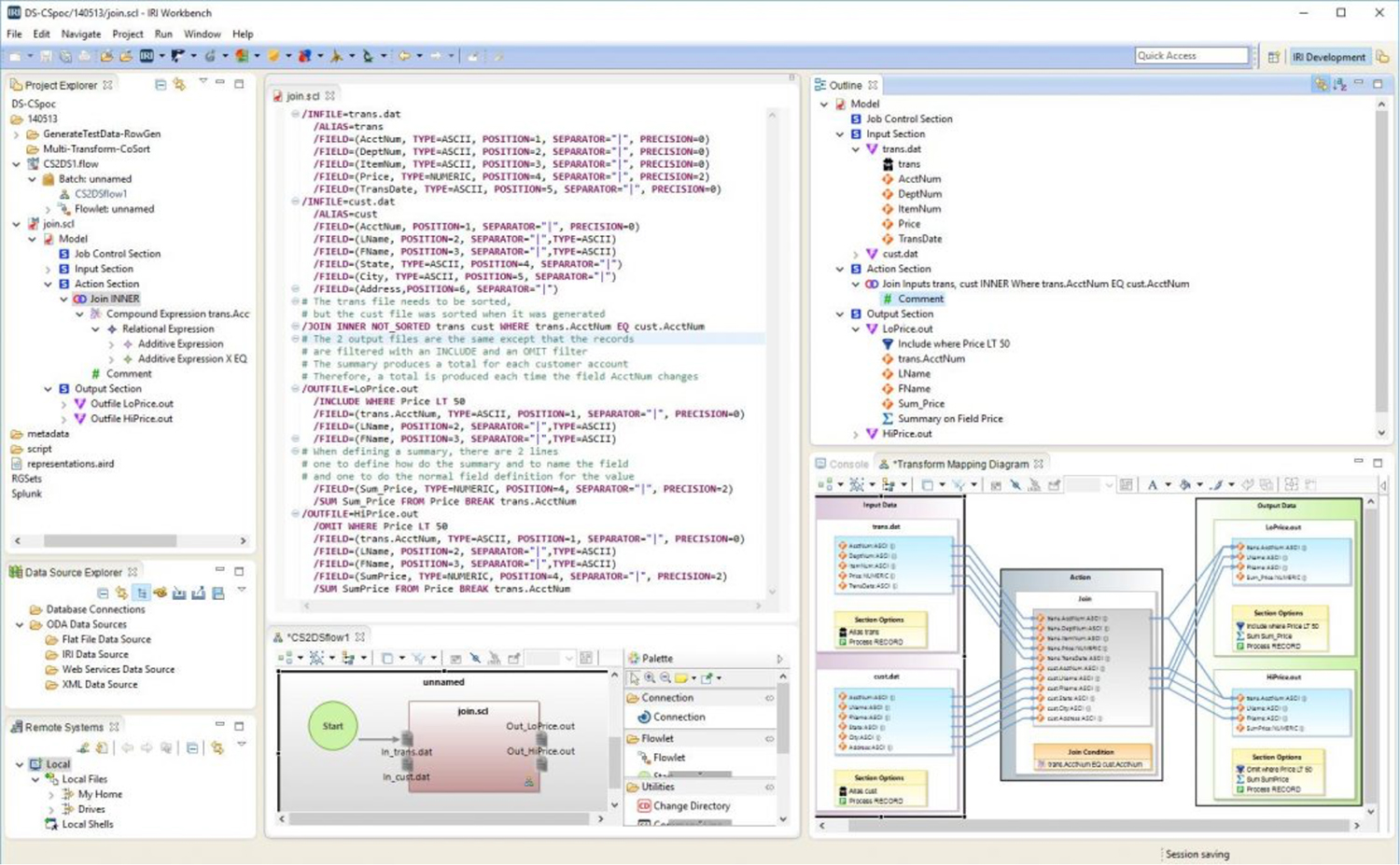
Fig – Using IRI Workbench’s 4GL
Other IRI products can be used in conjunction with Voracity’s data integration capabilities. DarkShield, for instance, is designed to find and mask PII in semi-structured and unstructured data. Moreover, it enables you to join this information to your relational or otherwise structured data in an automated fashion via a “textual ETL” process, generating additional intelligence. Similarly, Ripcurrent is a log-based CDC module for relational sources that provides real time replication and masking to incrementally refresh rows in test schema when production data changes. For data integration, it can be used to add row-specific transformations to a given table that trigger whenever data is inserted into or updated within it. These transformations happen automatically and in real time, although due to their nature they cannot consider values in rows outside the one they are operating on. Finally, the Workbench IDE is available to create your ETL jobs through its Eclipse-based UI, by leveraging its built-in wizards and 4GL tooling (which is to say, visual programming, although in this case it serialises ETL and other jobs into easily modifiable scripts).
In short, IRI Voracity provides useful ways to improve the efficiency and performance of your data integration processes without dramatically increasing costs or upsetting whichever solution you already have in place. While this position may seem a humble one, that impinges not at all on the benefits it can provide.