Data as an Asset



Analyst Coverage:
Treating data as an asset essentially requires four things:
- Knowing what data (or content) you have and where it is
- Understanding that data and how it relates to other data
- Ensuring that you can trust your data
- Protecting and securing your data
The first two of these functions are provided through data profiling. Data profiling tools may be used to statistically analyse the content of data sources, to discover where errors exist and to monitor (typically via a dashboard) the current status of errors within a particular data source. They may also be used to discover any relationships that exist within and across multiple (heterogeneous) data sources – see Data Discovery and Cataloguing – where data discovery is often provided as functionality within a data profiling tool (though there are specialist discovery tools, typically targeted at sensitive data). This is commonly used to support regulatory compliance (GDPR, CCPA and so forth), to support test data management, and for data asset discovery. Data cataloguing tools, which may make use of data discovery under the covers, provide a repository of information about a company’s data assets: what data is held, what format it is in, and within which (business) domains that data is relevant. The information should be collected automatically, and it may be classified further by geography, time, access control (who can see the data) and so on. Data Catalogues are indexed and searchable, and support self-service and collaboration. They are commonly used in conjunction with data preparation tools. Data profiling can also be used to drive data lineage. This allows you to monitor, record and visualise how and where data is flowing through – and being used within – your system. This is useful for understanding the flow of data within your system as a whole, as well as the movement of individual records as they move between parts of your environment.
Trusting your data is essential if you are going to make business decisions based on that information, and there are various tools that enable that trust, specifically data quality, data preparation and “data governance” products, with data profiling acting as a precursor to these other functions. Data governance has no authoritative definition, but in practice it is either the overarching process by which data assets are managed to ensure trustworthiness and accountability, or the highest level of said process, the one at which decisions are made and policy is created. This applies regardless of whether the data is in production, test or has been archived. The process as a whole can be thought of as having three ‘stages’: policy management, data stewardship, and data quality.
Data quality tools provide capabilities such as data matching (discovering duplicated records) and data enrichment (adding, say, geocoding or business data from the Internet), as well as data cleansing. Data quality is required for data governance and master data management (MDM). Some data quality products have specific capabilities to support, for example, data stewards and/or facilities such as issue tracking.
As far as data preparation is concerned, this takes the principles of data profiling and data quality and applies them to data that is, typically but not always, held within a data lake. As their name implies, the key ingredient of data preparation platforms is their ability to provide self-service capabilities that allow knowledgeable users (but who are not IT experts) to profile, combine, transform and cleanse relevant data prior to analysis: to “prepare” it. Tools in this category are targeted at business analysts and/or data scientists and work across all types of data (structured, semi-structured and unstructured) and across all data sources (both internal to the company and external).
There are two further elements to discuss with respect to trusting your data: firstly, there is the question of trust with respect to training data to support algorithmic processing and ensuring that the data is unbiased. This is discussed in Machine Learning & AI. Secondly, in addition to data governance there is also the issue of EUC (end user computing) governance, where EUCs consist of spreadsheet models, Access databases, TensorFlow models, Python scripts, Tableau reports, and so on and so forth. For details on this space see “EUC Governance”.
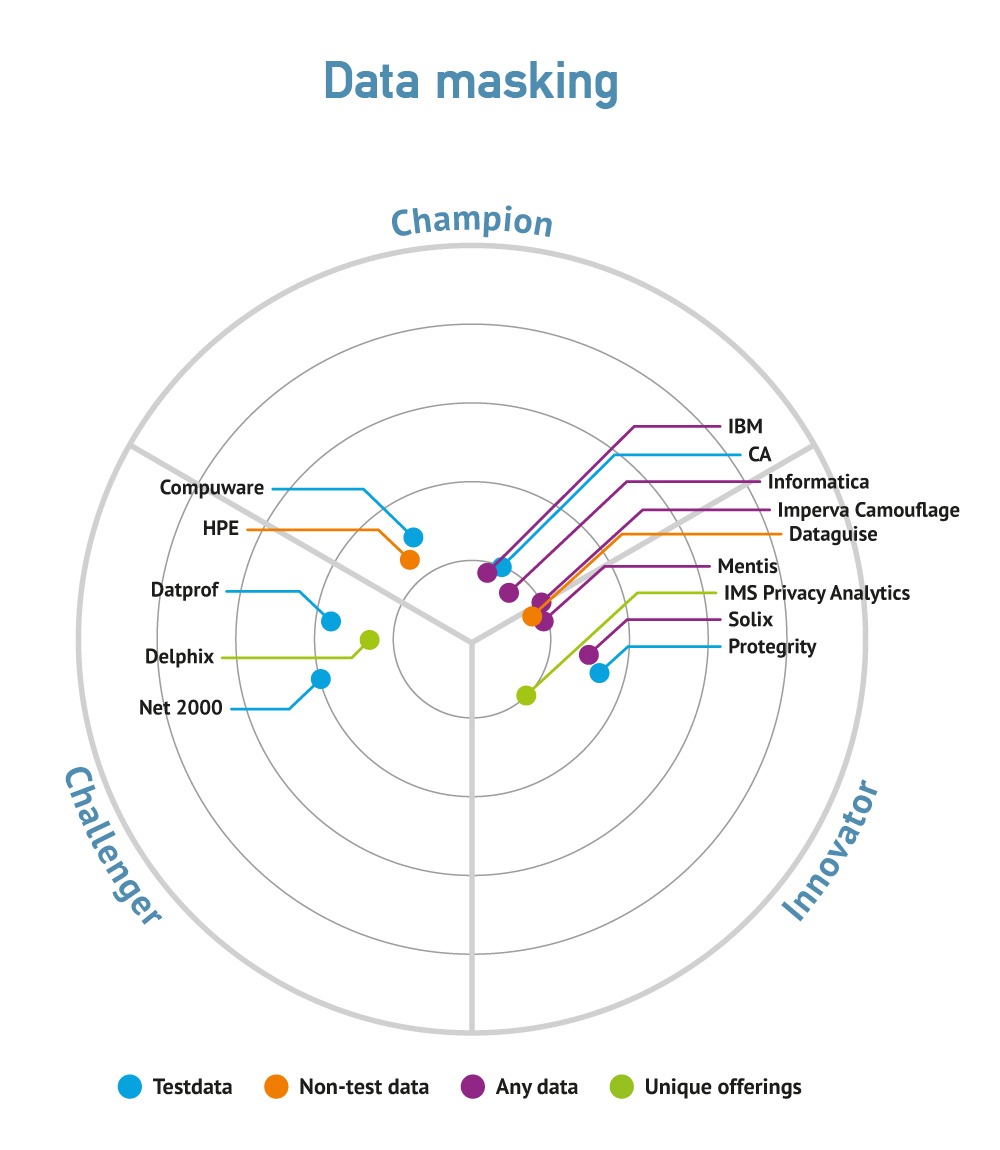
Finally, there is the question of protecting and securing your data assets. Much of this will fall under the Security heading (see Security) but dynamic “Data Masking” (see this for a discussion of techniques and requirements as well as Action: Test Data Management) is also relevant in this context. While static data masking is used in test and development environments, dynamic data masking is commonly used in conjunction with operational data in real-time, involving dynamically intercepting requests to the database (using SQL in the case of relevant sources but whatever is relevant in the case of, say, Hadoop) and masking any sensitive data that is returned. This is complementary to, or a replacement of, the sort of role-based access controls that are in use in many environments to prevent, for example, HR employees seeing the salary levels of executives. Masking of this type is being widely adopted to enable compliance with GDPR, CCPA, et al.
Data profiling collects statistics, classically on a column-by-column basis: details such as minimum and maximum values, number of times a value appears, number of nulls, invalid datatypes and so on. In other words, it both detects errors and creates profiles – often expressed as histograms – of the data being examined. Relevant tools also typically have the ability to monitor these statistics on an ongoing basis.
Data discovery is used to support data migration, as well as data archival, test data management, data masking and other technologies where it is important to understand the (referentially intact) business entities that you are managing or manipulating. This emphasis on business entities is also important in supporting collaboration between the business and IT because it is at this level that business analysts understand the data. Data discovery is also important in implementing MDM (master data management) because it enables the discovery of such things as matching keys and will provide precedence analysis. One major use case for data discovery is aimed at what might be called “understanding data landscapes”. This applies to very large enterprises that have hundreds or thousands of databases and the organisation simply wants to understand the relationships that exist across those databases. A specific subset of data discovery is sensitive data discovery, which focuses exclusively on discovering data covered by regulations such as GDPR and CPPA, again working in conjunction with data masking.
Data quality products provide tools to perform various automated or semi-automated tasks that ensure that data is as accurate, up-to-date and complete as you need it to be. This may, of course, be different for different types of data: you want your corporate financial figures to be absolutely accurate, but a margin of error is probably acceptable when it comes to mailing lists. Data quality products provide a range of functions. A data quality tool might simply alert you that there is an invalid postal code and then leave you to fix that; or the software, perhaps integrated with a relevant ERP or CRM product, might prevent the entry of an invalid post code altogether, prompting the user to re-enter that data. Some functions, such as adding a geocode to a location, can be completely automated while others will always require manual intervention. For example, when identifying potentially duplicate records the software can do this for you, and calculate the probability of a match, but it will require a business user or data steward to actually approve the match.
For further detail of the other elements of Data as an Asset – data preparation and catalogues, data governance, EUC governance and data masking – click the relevant links.
A more recent type of AI that burst into the public imagination in 2023 is generative AI, based on neural networks, which is capable of generating original content including documents, images, computer programs, essays, art and music. Generative AI is based on foundation models (also called large language models), which are trained on very large volumes of contents such as digital books and swathes of the internet. This type of AI is essentially a predictive algorithm. Ask it to produce an essay on the industrial revolution, a poem about rap music in the style of Wordsworth, a computer program subroutine in Python or an image of a space cruiser and it will do so. They can also critique or summarise an article, debug computer code or spot patterns in data. The current generative AIs are extremely good at languages and pattern recognition, though they have some limitations in various areas. The quality of their responses depends on the data they are trained on, and it is possible to take a foundation model as a basis and then train it on, for example, specific industry or company material, such as financial news and stock market prices.
Data profiling and data quality are both essential to good data governance and to any project involving the migration or movement of data, including MDM implementations. Quite simply, they are fundamental to the business being able to trust the data upon which it makes business decisions.
In the case of data profiling this can not only establish the scale of data quality problems, but it will also help data stewards to monitor the situation on an ongoing basis. Going further, data quality is about ensuring that data is fit for purpose; that it is accurate, timely and complete enough relative to the use to which it is put. As a technology, data quality can either be applied after the fact or in a preventative manner. Some data quality products have specific capabilities to support, for example, data stewards and/or facilities such as issue tracking.
Data discovery is important for compliance reasons (sensitive data) but also for rationalisation purposes. For example, if you have hundreds or thousands (or even tens of thousands) of databases then you may wish to rationalise that data landscape, but you can’t do that unless you have a thorough understanding of the relationships that exist between data elements held in different data stores. In practice, this understanding is also core to supporting the mutable enterprise.
Both data profiling and data quality are mature technologies and the most significant trend here is to implement machine learning within these products, especially for data matching where machine learning can help to reduce the number of false positives/negatives. The (sensitive) data discovery component of data profiling has also become more significant thanks to recent compliance requirements such as GDPR. Cloud-enabled and SaaS products (see Infrastructure) are, as might be expected, becoming increasingly common.
Data catalogues in particular are increasingly popular, and these are discussed in more detail in the Bloor Research article on “data preparation and catalogues”. An interesting concept is the combination of sensitive data discovery within a streaming environment. Io-Tahoe provides this.
In general, the market is split between those companies that just focus on providing data profiling and/or data quality (for example, Experian) and those that also offer either ETL (extract, transform and load) or MDM (master data management) or both. For instance, Informatica. Some of these “platforms” have been built from the ground up, such as that from SAS, while some others consist more of disparate bits that have been loosely bolted together. Many of these vendors also provide data governance solutions (IBM, Informatica, et al) and some also provide data preparation tools (SAS) and/or data catalogues. Both EUC governance and data masking are typically offered by distinct groups of vendors.
Notable recent announcements in this space are limited but include Redgate moving to a subscription first model and Zaloni (a data preparation/governance vendor) being certified on Cloudera’s platform. Also significant is Talend’s acquisition of Gamma Soft to provide change data capture. For developments in the EUC Governance space see here
Related Blog
- Welcome to Season 9 of SAP Let’s Talk Data:
- Ataccama unveil new AI agent feature
- Glad RAGs
- Helping to make AI more trustworthy with SAS
- Vector databases and their use in Generative AI
- IRI Data Classification
- Ultipa Graph approaches version 5.0
- SAS – who dares wins in database analytics
- Simplify ESG Data with Yotilla Data Warehouse Automation
- Stibo Systems CONNECT 2023
- Mainframe modernisation is now very much part of OpenText
- Data democratisation and Domo
- Men are from Mars, graphs are from Kobai Saturn
- Interlink Software update
- IBM AIOps
Related Research
- Fortra DSPM (Data Security Posture Management)
- Solix Sensitive Data Discovery
- K2view Sensitive Data Discovery
- Ataccama ONE Data Discovery
- BigID Next Sensitive Data Discovery
- Aiimi Workplace AI Sensitive Data Discovery
- DataSunrise Sensitive Data Discovery (2025)
- Business opportunities from managing and anonymizing healthcare information
- Data management strategies for financial services
- Master Data Management (2025)
- Informatica MDM
- SAP Master Data Governance (2025)
- Stibo – STEPping out
- IBM Master Data Management
- Agility
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community