QuasarDB
Update solution on February 28, 2020
QuasarDB is a NewSQL (looks relational but isn’t) column-oriented, time-series, distributed database that uses a peer-to-peer approach to support QuasarDB clusters. The overall architecture is illustrated in Figure 1, whereby you have a single unified approach from ingestion through to delivery rather than an environment that involves both orchestration and multiple protocols. Along with other features of the product (in-memory processing that leverages SIMD [single instruction, multiple data] processing, lock-free memory management, various caching algorithms, and on-the-fly in-memory compression [see later]) this leads to faster ingestion with the company claiming to support in excess of 2 TB per day for market data.

Fig 01 QuasarDB high-level architecture
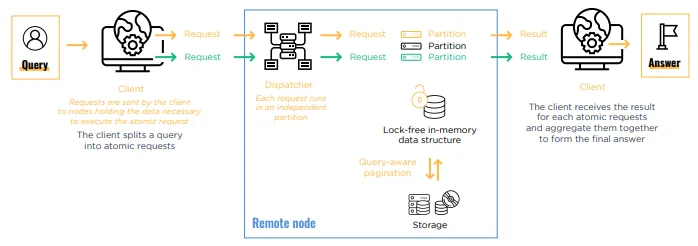
Fig 02 Query flow in QuasarDB
When a client inputs a query each (partitioned) QuasarDB cell handles the load transparently and addresses the hardware directly, in order to improve query performance, as illustrated in Figure 2.
Customer Quotes
“The integration of time-series oriented scalable data storage into our predictive analytics solution is the key to the effective deployment of predictive models on any type of object or platform.”
Tellmeplus
“Data is at the heart of our business, and we need to be sure that our analytics service is rock-solid and very fast. QuasarDB exceeded all our requirements, and the fully managed offering protects our resources from additional strain as we focus on building the best experience for our participants.”
LiquidityEdge
As a NewSQL database, QuasarDB is transactional and fully consistent, with support for Multi-version Concurrency Control (MVCC). It supports processing using primarily either Python or SQL, though Java, PHP and C++ are also supported, and there is a REST API. In the case of SQL – along with support for ODBC – this means that you could use tools such as Tableau or Qlik for visualisation, and we understand that additional connectors are currently in development.
Grafana is also supported and Kafka integration is provided, which is something notably absent from some other offerings. Also supported are Python Pandas and R.
A major differentiator for QuasarDB is in the way that it handles compression. Most companies that offer time-series databases either use a compression algorithm based on Facebook’s Gorilla or on LZ4 (the native lossless compression algorithm used in Hadoop), which is typically better than Gorilla. However, LZ4 is only really good for some use cases and can therefore vary in performance. In prior releases, QuasarDB had used a development of LZ4 but it has now introduced Delta4C (patent pending), which it claims to consistently out-perform LZ4, providing a constant speed of 12 GB/sec per core, which is an order of magnitude improvement. The only drawback is that Delta4C does not handle floating point values, though LZ4 is poor in this respect also. The company is working on this issue.
Apart from compression, which directly impacts on both storage requirements and performance, the other major point we should focus on is indexes. QuasarDB provides a zero-overhead index for the primary key, which is created automatically; and probabilistic, space-efficient secondary indexes for values (or, you can use tags). We understand that Michelin is using QuasarDB in conjunction with location-based data but the company does not have significant support for geo-spatial capabilities at this time, though relevant functionality, including support for spatio-temporal queries, is expected in 2020.
Finally, we should say that the footprint of QuasarDB is “a few Megabytes”, which is certainly small enough to support embedding in edge devices.
While we have described QuasarDB’s compression as a major differentiator for the company, it is really an enabler of its key differentiation, which is performance. This is focused on two markets: financial services (capital markets) and industrial and IoT applications such as connected cars. In all of these, performance is critical. In its most recent release, the company has introduced support for Prometheus, so that QuasarDB will now also be suitable for use in DevOps and other environments that are mostly about metrics and monitoring. Going back to performance, QuasarDB has published benchmarks comparing its ingestion rates, storage requirements and query response times to other leading time-series databases and, while we are always skeptical of benchmarks that are not independently verified, the results appear impressive.
The other major point to make about QuasarDB is that you can use SQL. This is by no means always the case in this market, with several other products using proprietary languages, some of which are quite obscure.
The Bottom Line
QuasarDB is not the most well known of time-series databases – perhaps because it is French rather than American – but it deserves to be considered alongside its more well-known counterparts.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community