Lumada Data Catalog
Update solution on June 22, 2020
The Lumada Data Catalog is a data catalogue targeted at both the enterprise data lake and traditional data environments. It provides a complete solution for data discovery, cataloguing and compliance on these platforms, and is particularly notable for its discovery process, which is based around using machine-learning driven “data fingerprinting” to tag data consistently and intelligently. This process is further enhanced by the collaborative and crowd-sourcing capabilities the product provides. Moreover, as we discuss in this paper, it can also be applied to specifically discovering sensitive data.
The Lumada Data Catalog supports a variety of data sources, including most major relational databases, several cloud-based products including Amazon S3, Microsoft Azure, and Google Cloud Platform, on-premises Hadoop-based big data platforms, and a variety of structured and semi-structured file formats including Avro, Parquet, delimited files, JSON, XML and others.
Hitachi Vantara correctly recognises that the majority of enterprises will have far too much data for searching for sensitive data manually to be a viable prospect. On the other hand, automated discovery can sometimes be too simplistic to determine whether data is truly sensitive, especially when that data is only sensitive indirectly. The company’s solution to this problem is data fingerprinting, its bespoke, machine learning driven AI for data discovery and tagging.
Data fingerprinting works by creating a “fingerprint” for each of your data fields. Each fingerprint is a collection of metadata – in some cases, more than 100 pieces of metadata – which includes information about both the content of your data as well as the context it exists in. Data fingerprinting can then intelligently and automatically classify and tag each of your fields based on its fingerprint. Once your data has been classified, it is exposed to your users as part of the data catalogue and is open to curation and crowdsourcing, the former of which drives data fingerprinting machine learning, thus improving its accuracy over time. Figure 1 illustrates how fields in a data set are tagged by data fingerprinting, with different confidence levels based on the likelihood that a particular tag applies.
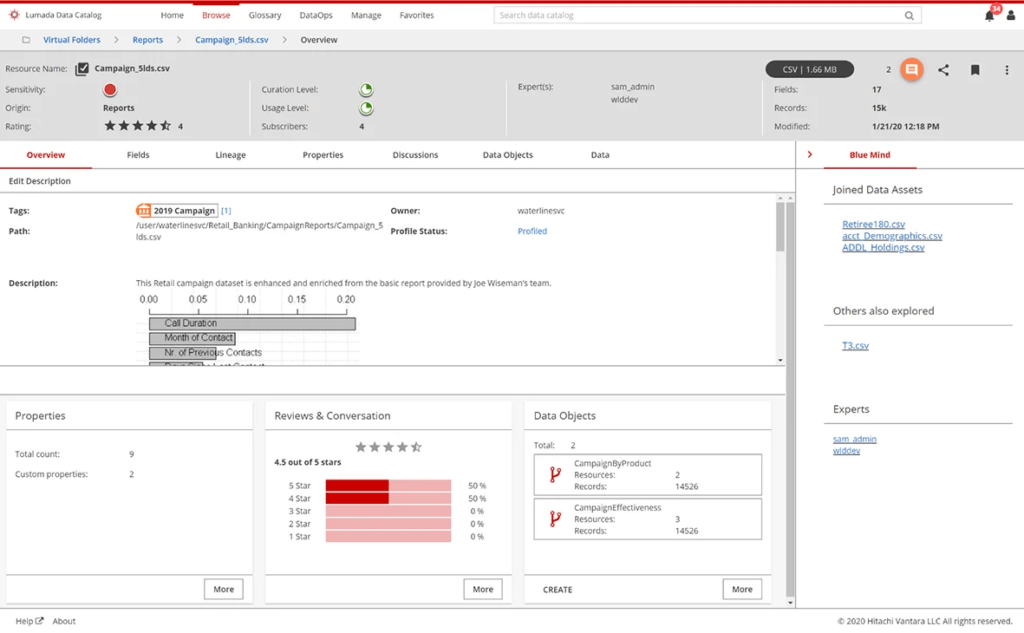
Fig 01 – Data fingerprinting using the Lumada Data Catalog
For the purposes of identifying sensitive data, a number of possible classifications are of interest, and in fact over 300 pre-defined and pre-trained tags are provided to identify and classify data that is sensitive under GDPR alone. What’s more, Lumada Data Catalog allows you to leverage tag-based rules to automatically tag data sets based on the fields they contain. For example, you could automatically tag your data sets as sensitive under GDPR if they contain fields tagged as first and last name, and where a field tagged as country contains data points corresponding to a European country. As you can tell from this example, these rules can mix data and metadata checks. What’s more, they are applied irrespective of data source, data format, and field names.
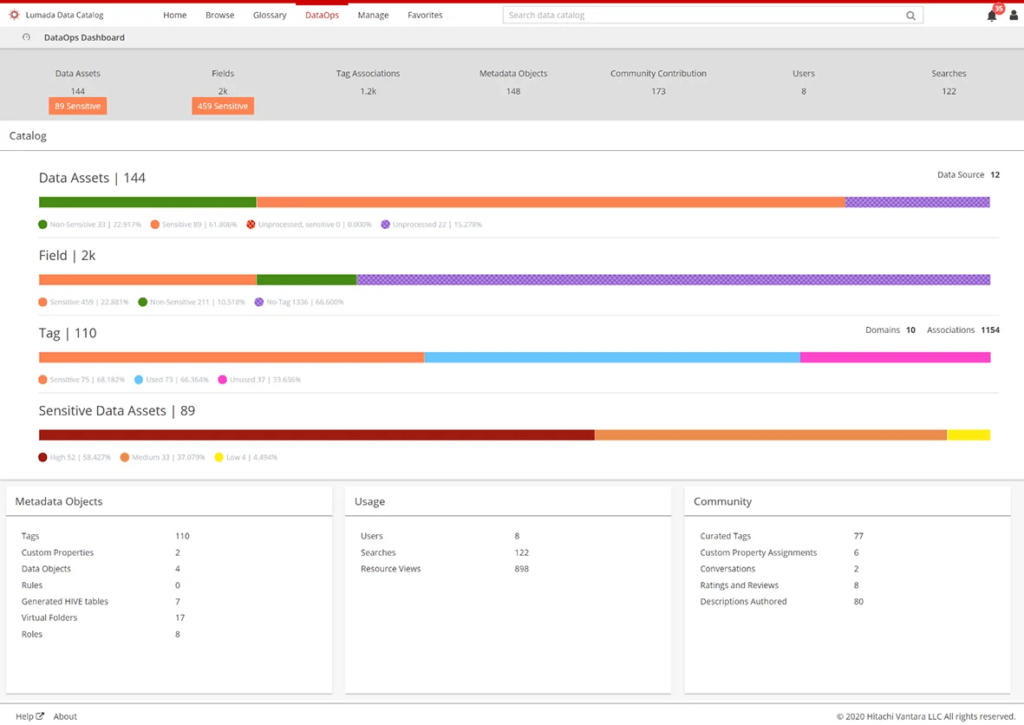
Fig 02 – Visually exploring data tables containing sensitive data
However, what if first and last names are in one table and country information is in another? With Lumada, you can visually explore any data tables that are related to the sensitive data you have already identified, as shown in Figure 2. This can be used to discover yet more sensitive data, and moreover, the software will automatically discover potential join conditions between these data sets and virtually join them using those conditions. This allows you to view them as a single data set. In turn, this can reveal additional sensitivity within your data that is only evident when it is seen in this way.
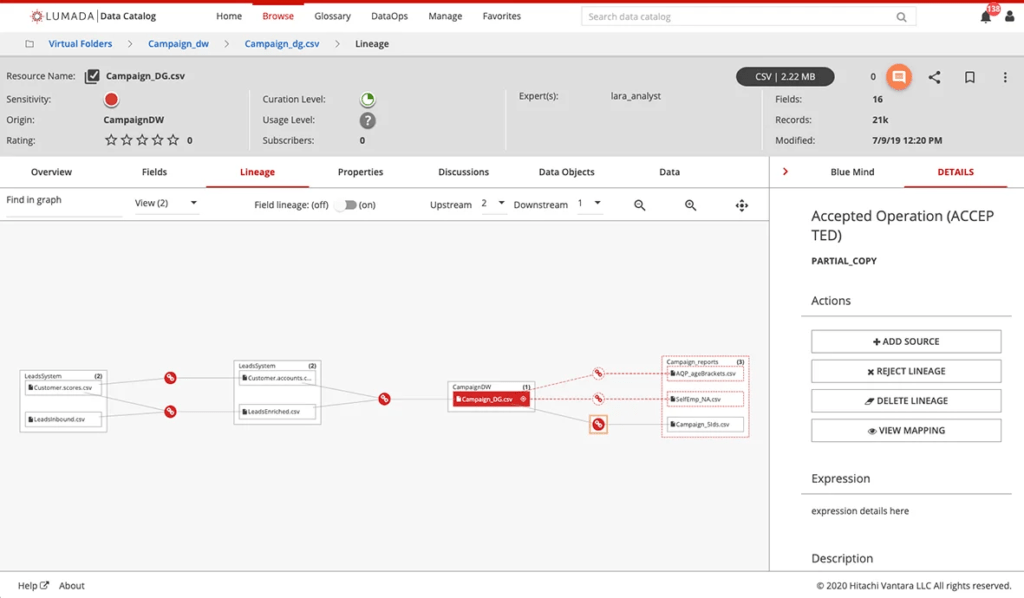
Fig 03 – Tracking data lineage with the Lumada Data Catalog
In addition, Lumada allows you to add custom properties to your data sets, which you can subsequently search on or filter by. For sensitive data, the utility here is that you can use these custom properties to store compliance metadata, such as the business purpose of your sensitive data. The product also provides visual, traversable tracking of data lineage, see Figure 3, which can either be imported from an existing source of lineage or inferred from your fingerprints. This capability may be useful for, say, locating data movement in and out of the EU. Finally, all of the searches and metadata available in the Lumada Data Catalog – including custom properties such as compliance metadata – are exposed via REST APIs, enabling integration with other compliance products.
Automated data discovery is essential for classifying your data consistently and comprehensively at an enterprise level, and this is just as true for sensitive data as it is for any other kind. Therefore, as a data catalogue, it should come as no surprise that Hitachi Vantara positions these features prominently. In this regard, Lumada’s adoption of machine learning in the form of data fingerprinting and the fingerprint system is notable.
The fingerprint system also has a number of features that are of particular benefit to sensitive data discovery. Fingerprints themselves contain a wealth of metadata, much of which concerns the context in which your data exists, and the rules engine that the product uses is able to operate in response to a combination of both metadata and data. Since whether or not any particular piece of data is sensitive can be highly complex and contextual, these are useful features for identifying the sensitive data in your environment.
The Bottom Line
The Lumada Data Catalog provides formidable sensitive data discovery capabilities as part of a data catalogue. If you are in the market for the latter, Lumada is a strong choice for the former.
Related Company
Connect with Us
Ready to Get Started
Learn how Bloor Research can support your organization’s journey toward a smarter, more secure future."
Connect with us Join Our Community