
Progress
Last Updated:
Analyst Coverage: David Norfolk, Philip Howard and Daniel Howard
Progress Software was founded in 1981 and has its HQ in Burlington, Massachusetts, with offices in 20+ countries. It employs over 3,000 staff and has over 100,000 enterprise customers. Progress has a quite wide range of products aimed at creating and deploying business applications. These include the MarkLogic data management platform.
Data Fabric with Progress MarkLogic
Last Updated: 12th March 2024
Mutable Award: Gold 2024
Progress MarkLogic is a data management platform, powered by a multi-model database that can natively store a wide variety of datatypes such as documents (XML and JSON files), geospatial data, relational data, semantic data, images and more. It could be considered a “semantic data platform” or documents store. The product represented its contents with a knowledge graph as far back as 2014, well before the idea was popularised further by the data fabric movement. In a modern interpretation of data fabric, governance and query are centralised. In the related approach known as data mesh both query and governance are decentralised. MarkLogic has a foot in both camps as it decentralises governance and centralises management and querying of the data.
Customer Quotes
“We’ve derived operational benefits in terms of cost reduction, efficiencies and, in analytics we’ve come up with better reporting mechanisms, which helps in risk management.”
Dr Alice Claire Augustine, Taxonomy Data Management Lead, Amgen
“Two years ago they used to do time-consuming flight-by-flight analysis. Today they can compare thousands of tests quickly – this is part of the multi-flight analysis revolution.”
Laurent Peltier, Test Data Processing Expert, Flight and Integration Test Centre, Airbus
Most data projects have to tackle the task of getting data out from operational systems into a separate store such as a data warehouse or data lake. This approach has a number of drawbacks. To begin with, it is usually carried out by developers who may not be intimately familiar with the context of the business data. To avoid duplication of common data like “product”, “asset” or “location”, some process of merging and matching of records will be needed, with consequent data transformations needed. Since most large companies have hundreds of different data sources (some have thousands) this process can be complex and expensive.
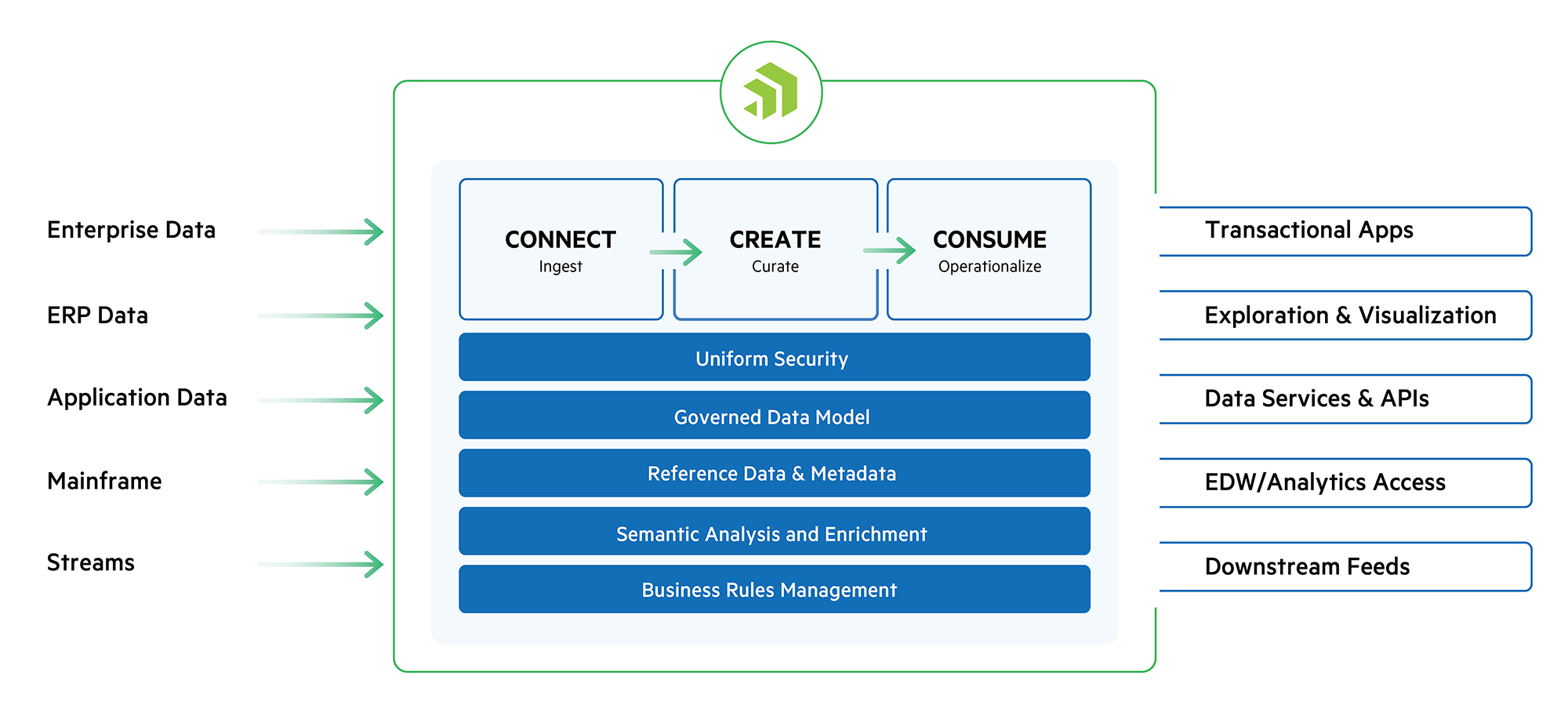
Fig 01 - MarkLogic-Powered Data Fabric
MarkLogic starts with a data fabric approach that has a knowledge graph, a store of metadata in a catalogue, and possibly some commonly used data. The data is represented by a model using business terms such as “customer”, “campaign” or “invoice”. MarkLogic manages both conceptual and logical data models, and can store conventional rows and columns of data as well as unstructured data like documents or images. The core platform has connectivity, security, a data model, metadata, semantic analysis and business rules management. MarkLogic has connectors to sources like Salesforce or SAP., which are accessed either via APIs where available or raw SQL where necessary. There is then a process of curating data, and the product has a data hub that includes matching and merging (based on their intellectual property rather than an OEM of a third party matching product as some other companies do). The product carries out semantic analysis and enrichment, and does reference data management, subject classification and annotation. Business rules management is also supported via an add-on product Progress Corticon, which may be specific to an industry or company. The product has specific support for querying complex data like bi-temporal, so goes beyond basic SQL for structured data. There are elaborate security capabilities down to field level including the dynamic redaction of fields.
MarkLogic has many elements of a modern data fabric architecture. In theory, the product can access data stored within it or pass queries out to source systems without needing to move data into the MarkLogic store, though in practice the latter turns out to be generally a lot more efficient. Some of their customers have quite large amounts of data up to the petabyte range.
The knowledge graph within MarkLogic has several navigation mechanisms tailored for both data engineers and data consumers. This includes an attractive visual diagramming tool that can be dynamically navigated. There is also a specialist way to visualise bi-temporal data, a datatype often neglected but which is important in certain industries like finance.
The bottom line
MarkLogic has many capabilities of a modern data fabric, or indeed data mesh, architecture. It has a mature knowledge graph with several ways to visualise the data, and is adept at handling complex data types such as bi-temporal, documents and semantic data, as well as regular structured data. Having been deployed by hundreds of customers, it is a proven product that is worth consideration, especially for companies having to deal with complex datatypes and metadata.
Mutable Award: Gold 2024

MarkLogic Data Hub
Last Updated: 3rd March 2021
Mutable Award: Platinum 2021
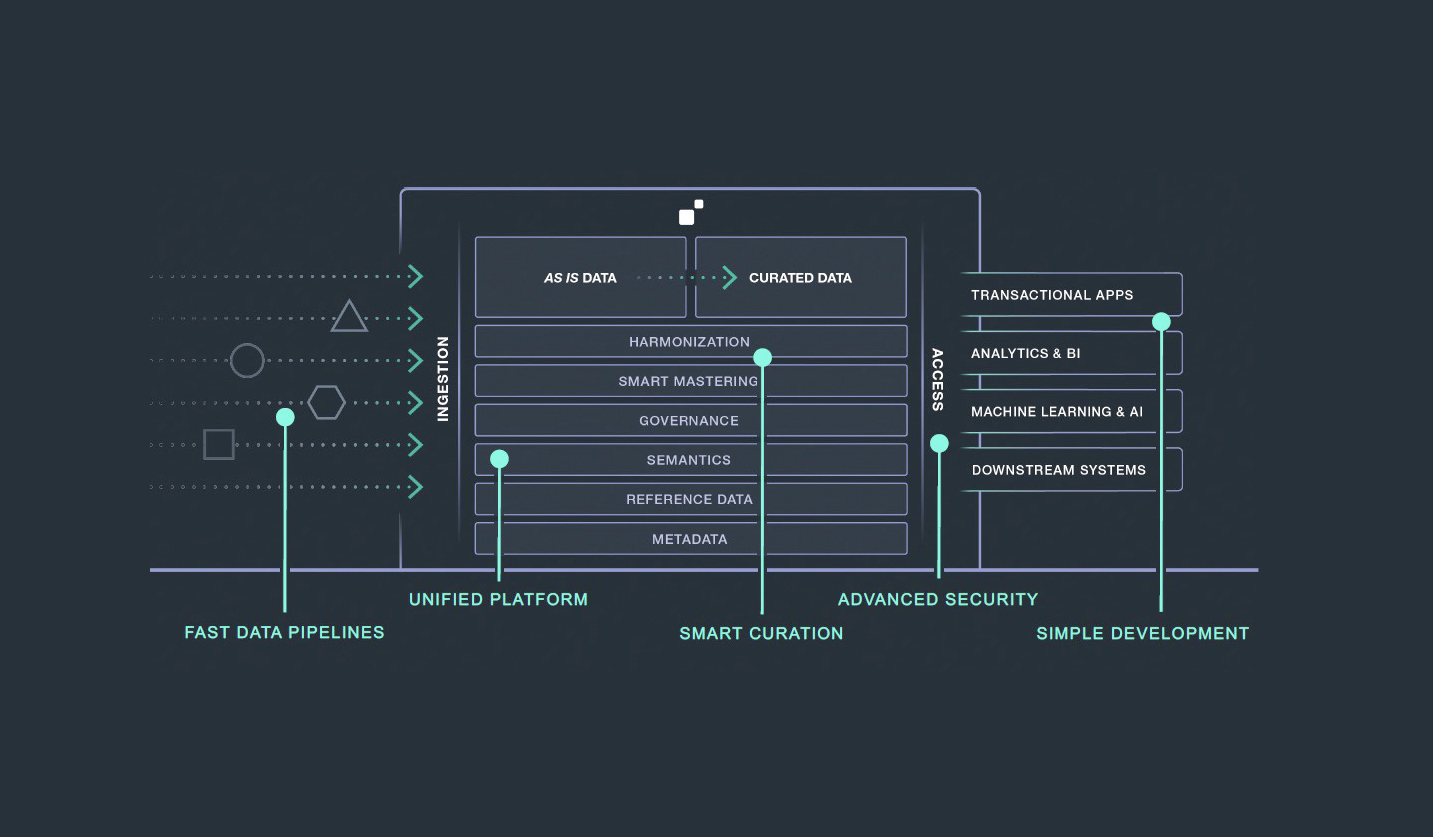
Fig 01 - The architecture of the MarkLogic Data Hub
MarkLogic Data Hub, whose architecture is shown in Figure 1, is a fully cloud-native platform for data storage, integration, operationalisation and governance. On-premises implementations are also possible. The product is built on top of MarkLogic Server, a multi-model database that is capable of handling graph, relational, and document data. MarkLogic’s offerings can be deployed either on-premises or in the cloud. The latter in particular is enabled via MarkLogic Data Hub Service, the company’s fully managed, multi-cloud data hub SaaS solution. Moreover, the company supports a gradual transition – what it terms a “pathway to the cloud” – from on-premises deployment, to self-managed cloud deployment, to the fully managed Data Hub Service.
Customer Quotes
“Critical to our 2nd century digitization strategy is not just data integration but business integration – which, of course, they go hand in hand. That is what MarkLogic delivers.”
Boeing
“With MarkLogic, we were able to do in months what we failed to do in years with our previous approach.”
Credit Suisse
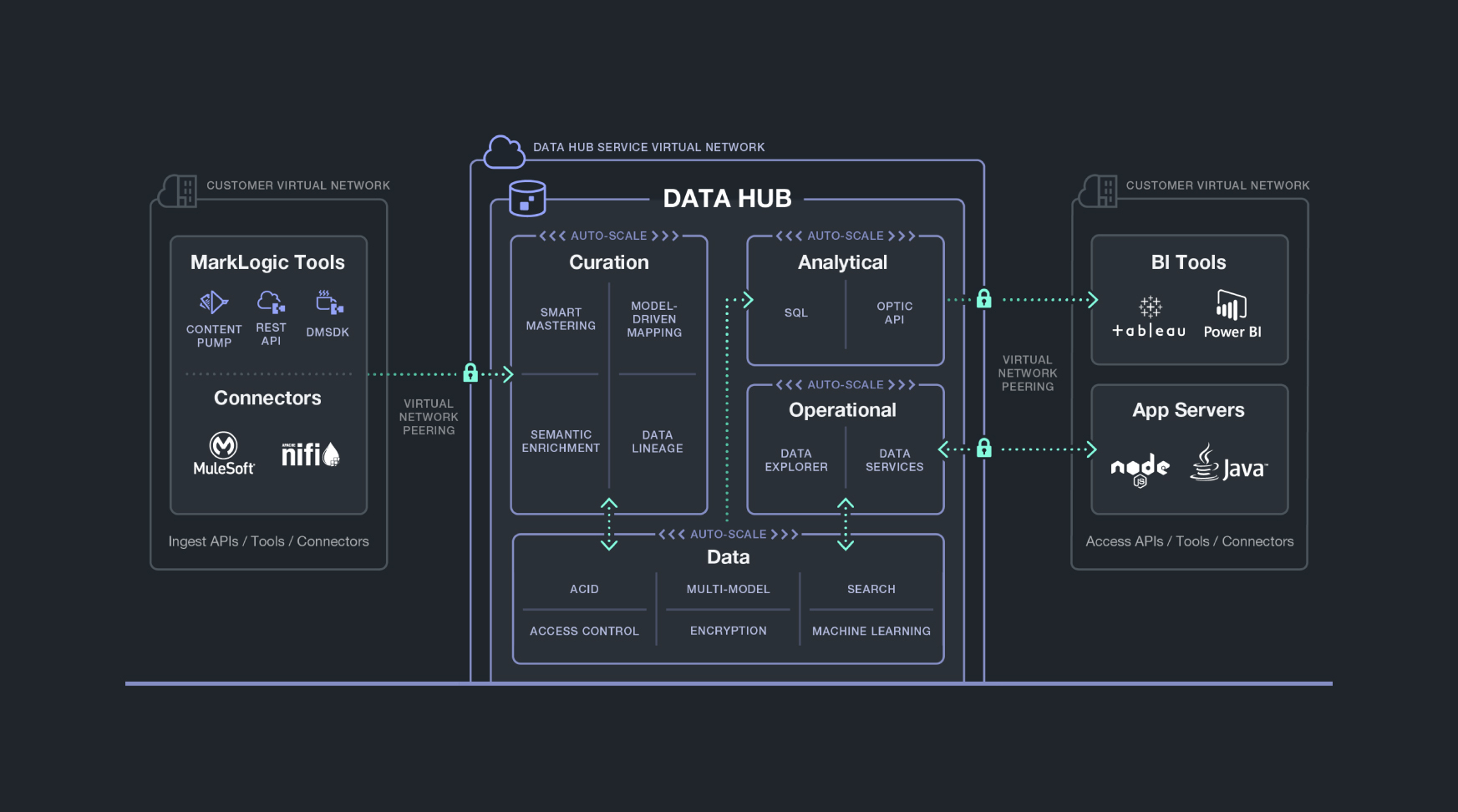
Fig 02 - MarkLogic Data Hub components
Figure 2 provides a more detailed view of how MarkLogic Data Hub works. However, some of this may take some explanation, especially with respect to data integration processes. In MarkLogic this is model-driven. That is, instead of building a one-to-one pipeline you build a source to model mapping and a model to target mapping. Imagine that you have 100 sources which might map to any of 10 targets. If you use a traditional point-to-point approach you need 1,000 pipelines. If you use a model-driven approach you need 110. The immediate benefits deriving from this approach are obvious: far less development and maintenance, as well as logical separation between the sources and targets. You can change a mapping, and test it, without interrupting existing processes. There are check-in and version control features to support updated mappings.
However, there are also less obvious benefits. What you are actually creating during this process is an entity model, or series of entity models, which represents an abstraction layer between source and targets, with semantic models that are persisted within the underlying database. This allows curation of that model, both in terms of data quality and, because of the semantic nature of models, support functions like classification and metadata management (including data lineage). In effect, it offers much the same capabilities as a data catalogue with the exception that you cannot automatically crawl data sources to create the catalogue. On the other hand, the underlying multi-model (graph) database allows you to construct a knowledge graph through which you can explore all the relationships that exist between different data elements. This is done through the Data Hub Central user interface, which provides a no/low-code environment targeted at domain experts rather than IT folk. In addition to allowing you to explore your data catalogue equivalent via a search interface it is also extensible, allowing you to define plug-ins for, say, extra data quality functions that are not provided out of the box. Automation and machine learning are implemented in various places across the Data Hub.
From a data integration perspective, MarkLogic refers to consumption models rather than targets. This is because the environment is by no means tied to populating data warehouses and data lakes but also supports direct feeds into business intelligence tools, machine learning platforms and applications.
More generally, MarkLogic Data Hub acts as a hub for data management on top of MarkLogic Server. This means that it inherits the latter’s multi-model approach, then exposes it via the unified data integration and management platform. It also offers a number of additional features, including data lineage tracking, fast data pipelines, and additional governance features. Most notably, it allows you to directly enforce policy rules on your queries at the code level, filtering the results in order to comply with the applied policy and thus embedding governance into the queries themselves. As a means of policy enforcement this is highly effective because it is present in your system at a deep level, which means it cannot be ignored or easily circumvented.
Finally, with respect to data privacy, GDPR-style permissions can be attached to models during the curation phases, and both redaction and anonymisation (data masking) are supported.
As a concept, the idea of putting an abstraction layer between sources and targets is a strong one. And implementing that on top of a multi-model database that supports a graph model provides powerful support for other data management functions. It is also worth commenting on the company’s pricing model. This is consumption-based. Moreover, the Data Hub Service is serverless and separates storage from compute, with different compute functions (say, loading data as opposed to curation processes) also separated. This is taken into account for pricing purposes, so it is as efficient as it possibly can be.
The Bottom Line
We are impressed with MarkLogic Data Hub. MarkLogic is less well known outside of its core markets but its innovation, and the agility of its solution mean that it should be considered a leading vendor.
Mutable Award: Platinum 2021

MarkLogic Data Hub Service and MarkLogic Server
Last Updated: 11th September 2020
Mutable Award: Gold 2020
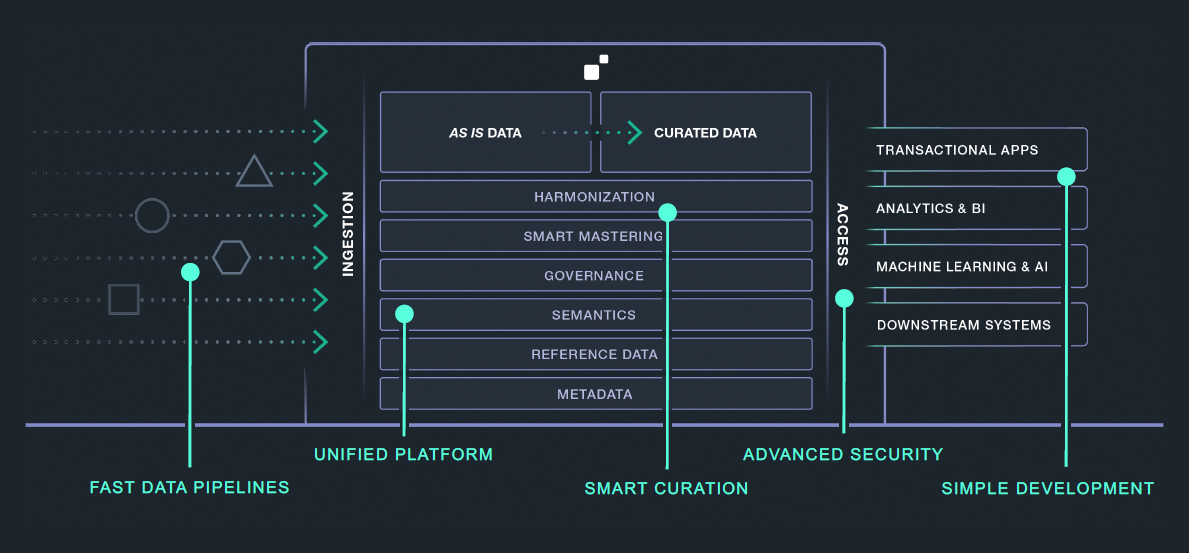
Fig 01 - MarkLogic Data Hub Platform architecture
MarkLogic Data Hub, whose architecture is shown in Figure 1, is a platform for data storage, integration, operationalisation and governance. It’s built on top of MarkLogic Server, a multi-model database that is capable of handling graph, relational, and document data. MarkLogic’s offerings can be deployed either on-premises or in the cloud. The latter in particular is enabled via MarkLogic Data Hub Service, the company’s fully managed, multi-cloud data hub SaaS solution. Moreover, the company supports a gradual transition – what it terms a “pathway to the cloud” – from on-premises deployment, to self-managed cloud deployment, to the fully managed Data Hub Service.
Customer Quotes
“I’ve never seen such a rich and a fast technology in 25 years career.”
Airbus
“MarkLogic’s search, semantics and security features made it optimal to serve as the foundation for the next generation of our catalog.”
Johnson & Johnson
MarkLogic Server serves as the storage layer for MarkLogic Data Hub. As a multi-model database, it can be used to store documents (including JSON, XML and flat text documents), relational data via tables, rows and columns, and graph data via RDF triples (although technically it uses quads – which means it supports named graphs. The database is ACID compliant with immediate consistency, and there are enterprise grade features available such as high availability, resilience and so forth. Security capabilities are also provided, including encryption and key management, role-based security, redaction and even data masking. As far as graph is concerned, it supports inferencing via backward chaining, and there are built-in semantic search capabilities as well as (bi-)temporal and geospatial functionality.
Appropriate query support is provided for each model: search for documents, SQL for relational data, and SPARQL for graph data. The latter also supports GraphQL and GeoSPARQL. MarkLogic also provides its Optic API for multi-model querying using a combination of the aforementioned query languages. Notably, relational and graph data in MarkLogic Server leverage the same index technology, meaning that you can query the same data as either a set of triples or as rows and columns. All queries are composable between types of model, and consistency is maintained across all models that represent the same data.
You can also leverage multiple models simultaneously. For example – in fact, this is a typical use case – you can use MarkLogic to build a knowledge graph where the entities are documents and the relationships are triples. Among other things, this means that the nodes in your graph can contain properties (read: metadata) in and of themselves, without requiring additional nodes in the graph. This allows you to store a wealth of property information within your graphs, and thus provide fodder for detailed searching and querying, without fear that the size of your graphs will balloon out of all reasonable proportion.
Alternatively (or additionally), you can annotate your documents using triples or embed your triples inside of your documents. By partitioning your set of triples between your documents, you can leverage document search to rapidly locate which documents – and therefore which subset of your triples – are relevant to your query, then apply your query strictly to that subset. This has benefits for speed and scalability.
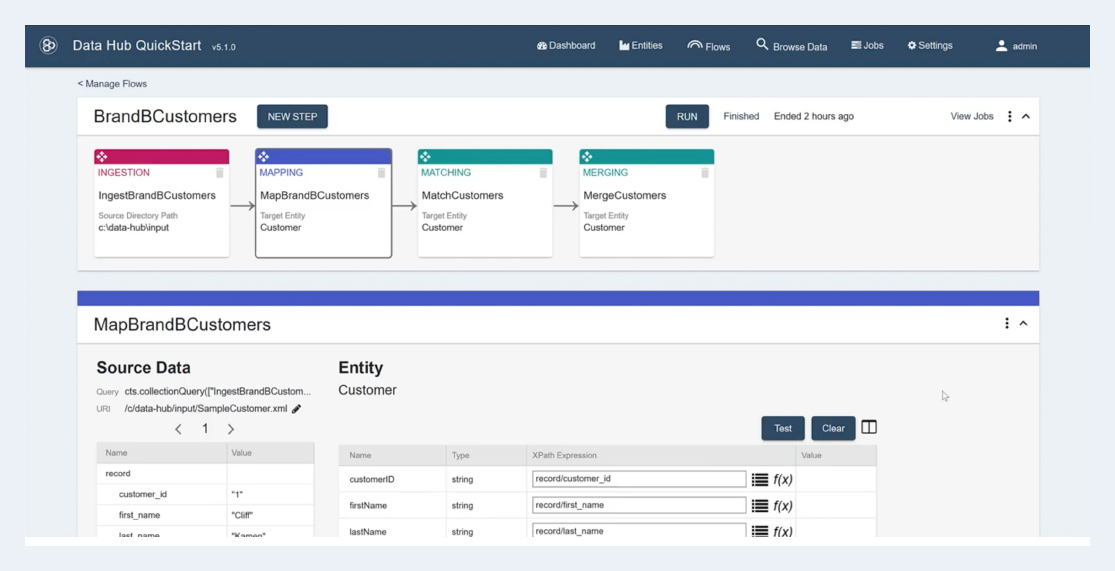
Fig 02 - MarkLogic Data Hub QuickStart
As far as the MarkLogic Data Hub itself is concerned, it acts as a hub for data management on top of MarkLogic Server. This means that it inherits the latter’s multi-model approach, then exposes it via a unified data integration and management platform. It also offers a number of additional features, including data lineage tracking, fast data pipelines, a “QuickStart” user interface (see Figure 2), and additional governance features. Most notably, it allows you to directly enforce policy rules on your queries at the code level, filtering the results in order to comply with the applied policy and thus embedding governance into the queries themselves. As a means of policy enforcement this is highly effective because it is present in your system at a deep level, which means it cannot be ignored or easily circumvented.
MarkLogic Server’s greatest selling point is undoubtedly the data agility that users get because it is multi-model and has schema flexibility. Being able to leverage graph, relational and document data interchangeably allows you to choose the right tool for the right job, and moreover, leveraging them in combination can create a solution that is more than the sum of its parts. Leveraging documents inside of graphs, and triples inside of documents, are particularly strong examples of this. The latter enables MarkLogic’s query optimisation, while the former allows you to store much more property information in your graph than would normally be practical. Moreover, the document format allows you to store information as needed, without regard for whether it fits into a rigid schema. This enables you to retain all relevant information, and thus provide a complete business context and provenance for each of the data assets within your (knowledge) graph.
MarkLogic Data Hub adds to this by providing a window into your multi-model data. It gives you multiple lenses with which to view your data (notably, relational and graph) and in general acts as a unified platform for interacting with and curating your graph, relational and document data. Its unique (and, as already indicated, highly effective) approach to policy management – which could more appropriately be described as policy enforcement – is worth noting as well.
The Bottom Line
MarkLogic Server excels as a multi-model database not only because it gives you an expanded range of options for storing data, but because it provides ways for those options to interoperate, and thereby produce synergies that would otherwise not be possible. MarkLogic Data Hub builds on this foundation by providing fast ingestion, curation, and data access. In short, if you want to leverage graph, relational and document data together, you should be looking at MarkLogic.
Mutable Award: Gold 2020

Commentary
Research

Data Fabric

Data Fabric with Progress MarkLogic

Graph Databases (2023)

(Cloud) Data Management Platforms

MarkLogic Data Hub

Graph Database (2020)
