
Data at Rest
Last Updated:
Analyst Coverage: Philip Howard and Daniel Howard
Data is either in a particular place (or places) or it is being moved between places. The former is referred to as “Data at rest” and the latter as “Data in motion”. When data is at rest it needs not just to be stored somewhere, but secured (see Security), managed and governed (see Data as an Asset), to a greater or less extent depending on the type of data involved.
It is important to distinguish between data and content. The latter is holistic, the former is not. For example, a document is complete in and of itself, but data per se is not: “37.5” might be stored in a database as a piece of data, but it is useless information without context. What is this 37.5? Is it a price, a total or a measurement? Does it refer to a product, a shopping cart or shipping costs? For data to be holistic it needs to be stored as a “data record” that details all of this contextual information. This difference mandates a somewhat different approach to the storage and management of data versus content, with the technology for the former being referred to as a database management system (DBMS) or simply “database”, and the latter using what are known as content management systems (CMS). However, both of these approaches may be treated as providing the storage and management of data at rest. Moreover, almost all content stores leverage an underlying database.
A further distinction needs to be borne in mind with respect to the creation and usage of data or content. Some of this is created and consumed by users – typically known as EUCAs (end-user computing assets) – while other information essentially consists of corporate data.
The ways in which these two sorts of data are stored and managed are very different:
- EUCAs are typically stored in file systems or spreadsheets that have very limited, if any, in-built control, management, security or governance capabilities. Such environments require external software capabilities for management and control purposes if they are to be deployed at an enterprise level. These are discussed under the heading “Data as an Asset”.
- Corporate data is typically stored and managed through the use of a database or content management system. The key point here is that management and security capabilities are provided as intrinsic features of the environment rather than something that needs to be added on, though complementary technologies such as Database Activity Monitoring (who is doing what with your data/content – see Security) or Database Performance Management (technologies to help improve performance) can improve these capabilities further.
Databases and content management systems do four basic things, allowing the Creation, Retrieval, Updating and Deletion (CRUD) of data/content relevant to that particular system. That said, there are some differences in capabilities, depending on use case. For example, if you are storing documents, then it will often be the case that you should not be able to update these: if a new version is produced, then that should precisely act as a new version, without replacing the old one. Note that content management systems all typically have this capability. Some databases offer an “append only” capability that fulfils the same function.
Similarly, deletion of data or content is sometimes a no-no. Or, at least, the ability to delete data is subject to control by corporate policies or to meet regulatory requirements such as “legal hold”. Again, this is commonplace for content management systems and is supported by append-only databases. Archival systems commonly add requisite capabilities to underlying database architectures.
Leaving these specialist requirements aside, it should be borne in mind that a content management system effectively consists of a software layer that overlays a conventional database of some sort. Thus any discussion of what a database does is also pertinent to content management. This is not entirely true: there are CMS offerings that consist of version control and other capabilities implemented on top of a flat file structure, but these are very much in the minority.
As far as databases are concerned, these are fundamentally of three types:
- Those that focus on optimal performance for the creation and updating of data. Traditionally, these were referred to as “transactional databases” because they principally supported the processing of business transactions. However, “operational databases” is coming into vogue as a term that encompasses not just transactions but also the sort of operational detail that might be involved in IoT (Internet of Things) processes, for example.
- Those that focus on optimal performance for the retrieval of data. Historically, transactional databases, while providing query capabilities (the R in CRUD), were focused on optimal processing for transactions, which meant that long or complex queries took too long to run. As result, various types of analytic databases (often referred to as data warehouses, data lakes or even data lakehouses) were developed. Relevant data was moved (see data in motion) from the transactional into the analytic environment where it can be analysed with optimal performance.
- Hybrid databases that attempt to do both, which includes some graph databases.
While these are the three basic foci there are, of course, a variety of considerations that complicate this story. This is particularly true with respect to performance: a variety of products are on the market to help improve performance, both with respect to the performance of the database itself, and of the general processing environment. The latter is of particular interest, not least because its resolution often involves the use of further database technology (such as a data fabrics or data mesh) or the use of an additional database to act as an in-memory cache.
However, performance is not always the be all and end all for data or content store performance. For example, a database dedicated to human resources is not subject to the same performance constraints as transactional systems. If a member of staff calls in sick and you need to assign someone else to fulfil their role you don’t need the sort of sub-millisecond response that you want for trading on capital markets.
Finally, there are, of course, lots of names for a variety of database types: relational databases, operational databases, transactional databases, analytic databases (data warehouses, data lakes and so forth), object stores, object-oriented databases, hybrid databases (HTAP: hybrid transactional and analytic processing) databases and variations thereof, NoSQL (Not or Not only SQL) databases, time-series databases (allows real-time monitoring and analysis of time-series data), spatial databases (more often a feature rather than a database per se), temporal databases (ditto), graph databases (including both property graph and RDF databases), in-memory databases, multi-dimensional databases, multivalue databases, XML databases, associative databases, NewSQL databases, and so on and so forth. And then there are content management systems, which also come in various flavours.
The short answer is everybody. You can’t run a business of any size without recording details of what you sell and who to, what you buy and who from, what staff you employ and what their skills are. In practice every organisation beyond a minimal size will require one or more databases. Many large organisations have hundreds or thousands of databases and some even count their databases in the tens of thousands though some of these will be real or virtual duplicates for recovery purposes or to support testing environments (see Action: “Test data management”). In addition, many enterprises, in both the public and private sector, will require one or more content management systems to store legal documents, medical records, CCTV footage or other types of content.
In practice, every department will need at least access to a data or content store if not their own dedicated environment. In some cases, even a single department may require the use of multiple databases. To give two extreme examples: the UK branch of one bank that trades on capital markets leverages three separate databases. One for today’s trades, one for this month’s trades and one for historic trades. At the other end of the spectrum we know of one company where the cleaning staff have access to a central database from which they can not only keep a track of their purchases but also analyse their performance.
Especially notable are graph and time-series databases. The former allows the creation of knowledge graphs as well as providing operational and (complex) analytic capabilities, which have widespread application. The latter provides real-time performance monitoring of operational processes (including database performance) and will be of interest both to database administrators and to those responsible for plant and machinery performance more generally. Spatial capabilities are particularly important wherever geography is an issue, for example in logistics, insurance, telecommunications and so on.
For obvious reasons trends come and go: the clue is in the name. Some which have been prevalent in recent years that have passed their sell-by date include “big data” (useful initially but now ubiquitous), “in-memory” databases (all databases exploit memory), “NoSQL” databases (not that they have gone away just that it’s no longer a useful distinction), “cloud” anything and “open source” anything (both ditto). One much talked about potential trend has been database leverage of GPUs. While there are products that do this, we have yet to see this technology really take off.
Some more established trends have already been discussed, at least partially. There is, for example, an increasing trend amongst analytic database providers to include spatial capabilities and to provide support for graph algorithms. This involves parallelising these query algorithms so that performance is appropriate. However, some graph algorithms cannot be parallelised and if you need to use any of these you will need a specific graph database. Time-series databases have also been mentioned and their functions have not – as yet – been subsumed within other database technologies, which is typically what happens over time.
In this context, one notable trend is towards multi-model databases, where you can instantiate the database as a graph database, a document database, a relational database, a key-value store or some other sort of database, or a combination thereof. A key requirement in such environments is that a single API can be used to address each model, otherwise you might as well just have a series of individual databases. One major advantage of multi-model databases is that they leverage the mutable principle: a single product that is adaptable for multiple purposes.
Also trending are object stores and data fabrics (again, employing mutability). The former provides relatively inexpensive storage of data that is required for long-term (rather than immediate) analytic purposes as well as for archival. There are multiple definitions of data fabrics, but they represent an architecture that leverages (data mesh) software so that all enterprise data assets, data stores and associated architectural constructs can work together. In practice, data fabrics leverage data virtualisation (see Data in Motion), of which they are an evolution.
Finally, as far as contact management is concerned, a current trend is to “headless” content management where the content store is exactly that, and is decoupled from the presentation layer. Such systems are accessed via an API that allows content to be displayed on any device, without the need for the underlying system to provide any sort of front-end or presentation layer.
The website www.db-engines.com lists 395 database products, while Wikipedia lists more than 150 content management systems. No doubt, some products are left off these lists. Whatever the exact number it would therefore be fruitless to try to discuss them all here, and invidious to try to pull out market leaders (other than the 800lb gorillas like IBM, Microsoft, Oracle and so forth), not least because these are use case dependent. Nevertheless, it is worth highlighting some relevant recent moves.
Vendors are increasingly partnering with the major Cloud providers, perhaps most notably with Teradata (see analytic databases) partnering with Microsoft Azure, and Exasol announcing a SaaS offering on AWS. Also in the analytic database space, multiple smaller companies have announced partnerships with Snowflake. Similarly in-database machine learning is becoming common, most notably with MariaDB (which is in the process of going public) partnering with MindsDB, and Oracle introducing MySQL Heatwave.
Other important partnership announcements include Yellowbrick and Nippon Information & Communications Corporation for the former to target the Japanese market, Software AG partnering with Silver Lake for a 344m Euro investment, and SingleStore (which has changed its name from MemSQL) with IBM. Cloudian’s HyperStore Object Storage now supports SQL Server.
There have also been some important acquisitions (announced or completed). Oracle has acquired Cerner Corporation to increase its presence in the Healthcare and Life Sciences sectors. Coincidentally, Databricks has announced a lakehouse platform for these same industries. It has also acquired the German start-up 8080 Labs, to support moves into supporting low-code/no-code development. Starburst, meanwhile, has bought Varada (data lake analytics accelerator) and announced partnerships with both Immuta (security) and Aerospike, which itself has announced native support for JSON data models. MarkLogic has acquired SmartLogic (metadata management) and Broadcom (technically a database vendor since it has the legacy CA-Datacom and CA-IDMS in its portfolio) has acquired VMWare. It will be interesting to see who Broadcom buys next.
Further announcements include the introduction of the Atlassian Data Lake within that company’s platform, and the release of the Adaptigent Intelligent Caching as a rival to the use of Redis. For details of recent developments in the graph database space see “graph databases”.



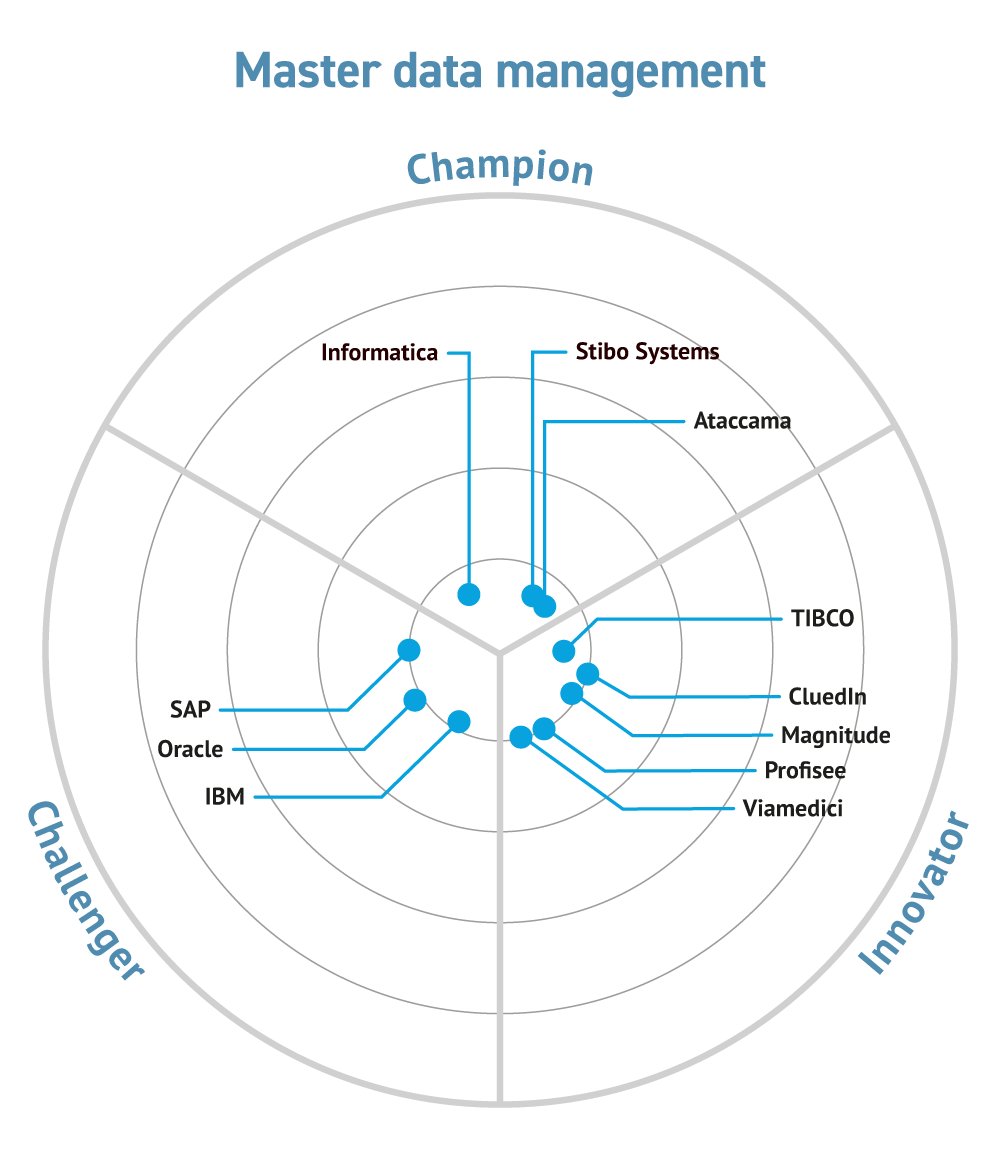
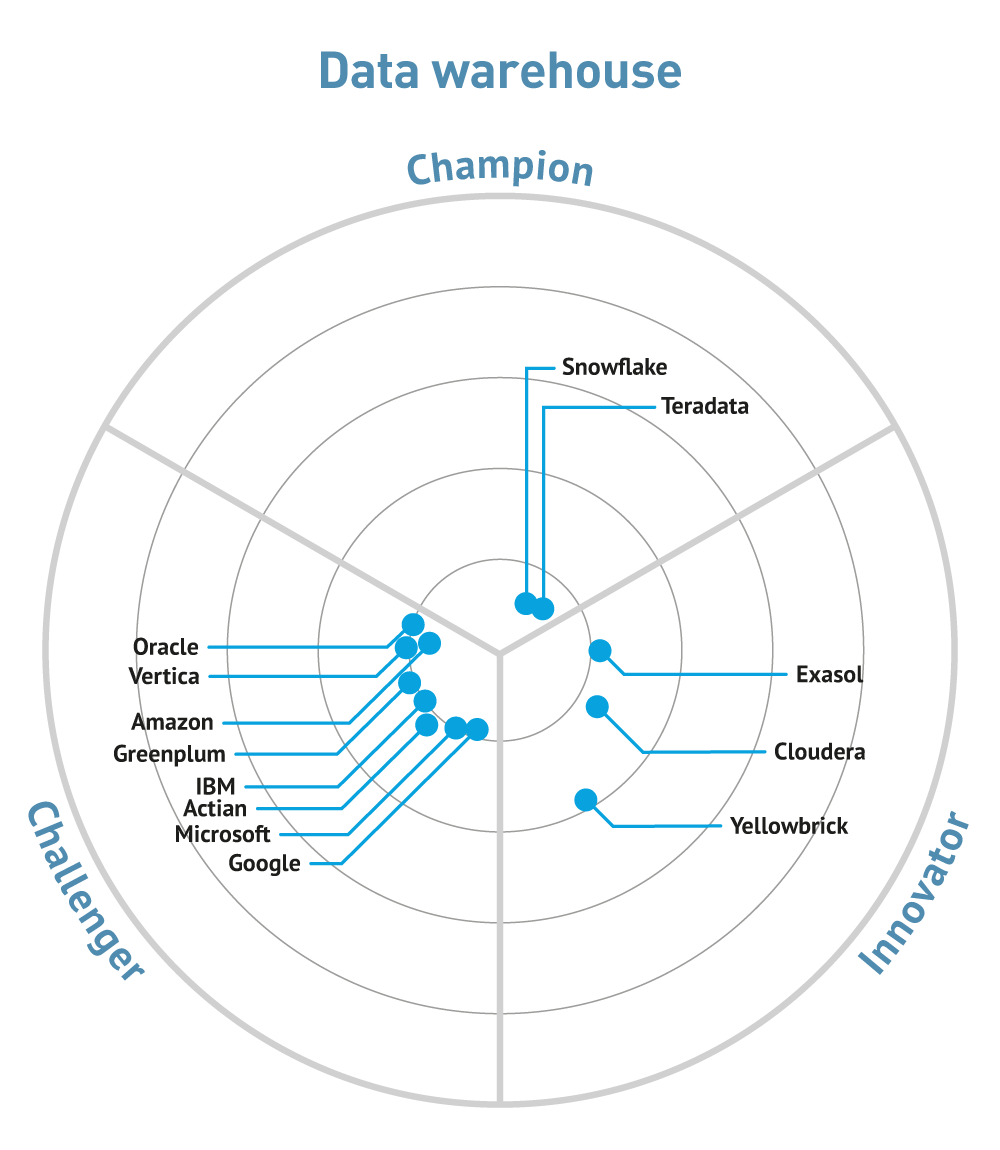
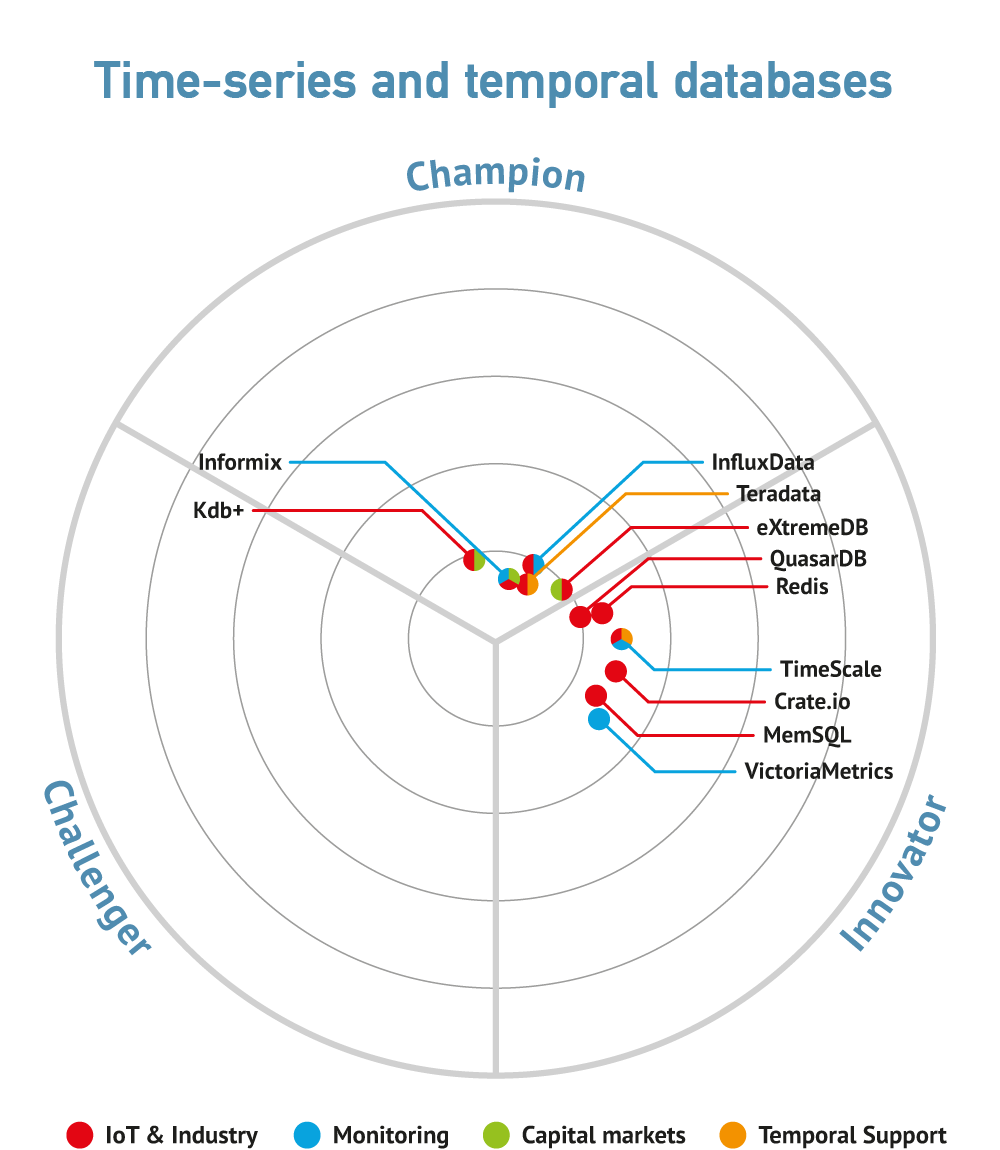
Commentary
Solutions









These organisations are also known to offer solutions:
- Atlassian
- Broadcom
- Cloudian
- Databricks
- Denodo
- Fivetran
- Fluree
- Incorta
- Matillion
- MindsDB
- OpenText
- Silver Lake
- Snowflake
- Software AG
- Syniti
Research

Data Governance (2024)

Building AI using Ultipa Graph

Ultipa – the Powerhouse of the graph world

The Rise of the Private Data Cloud

Solix – Data Governance from Archiving to AI

data.world

erwin Data Intelligence by Quest (2024)
