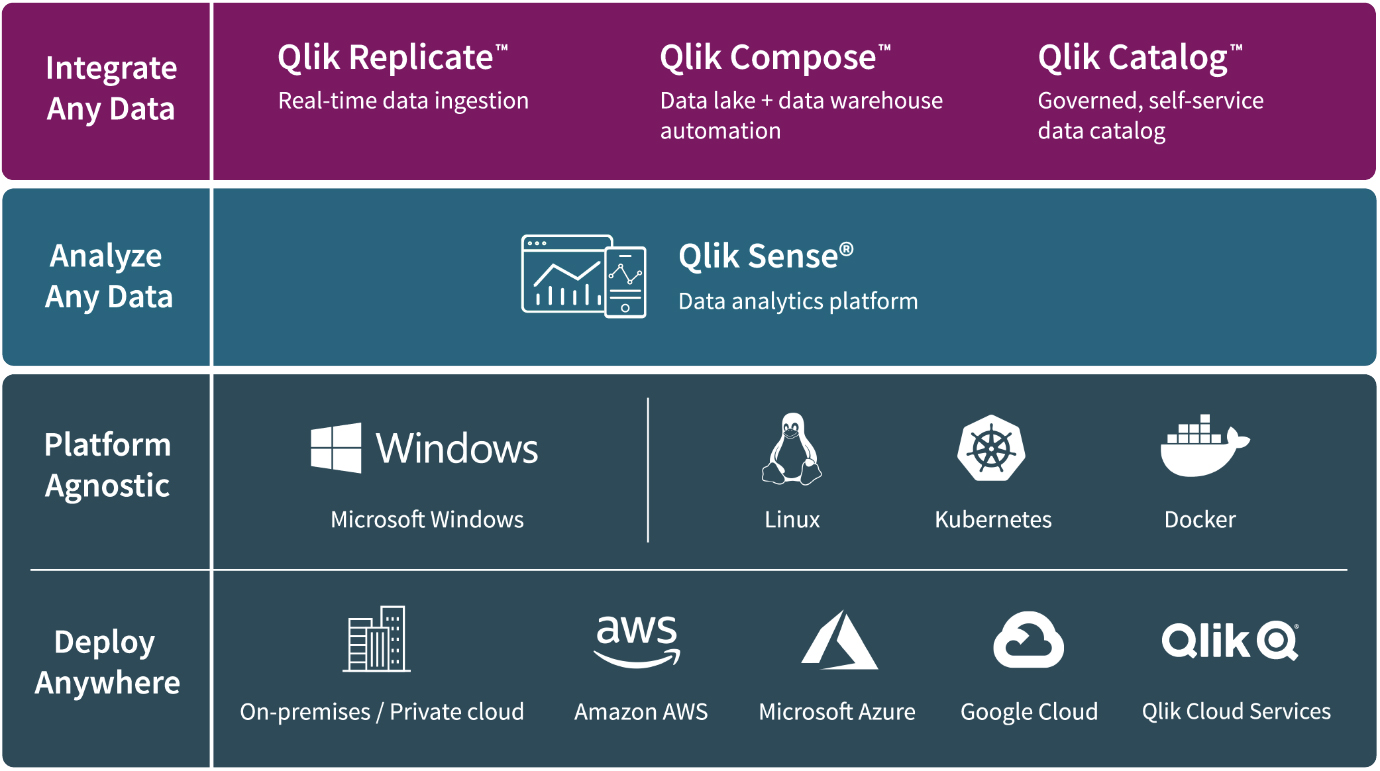
Compared to other vendors in the data integration space Qlik has taken the road less travelled. While many vendors are focused on providing traditional ETL (extract, transform and load) or ELT capabilities, Qlik’s approach is to bulk load data into your data warehouse/lake and then keep the environment up-to-date through CDC. For companies migrating from, say, and on-premises Teradata warehouse to an in-cloud Snowflake implementation, this makes a lot of sense. If you were setting up a data warehouse for the first time, perhaps not so much. You also lose out on some traditional capabilities of ETL tools, such B2B integration but you could always do that separately if that is a concern.
The other major way in which the Qlik Data Integration Platform differs from more conventional tools is that data profiling and data quality capabilities are reserved for the data preparation functions alongside Data Catalog, which includes engines for both filtering and transformations.
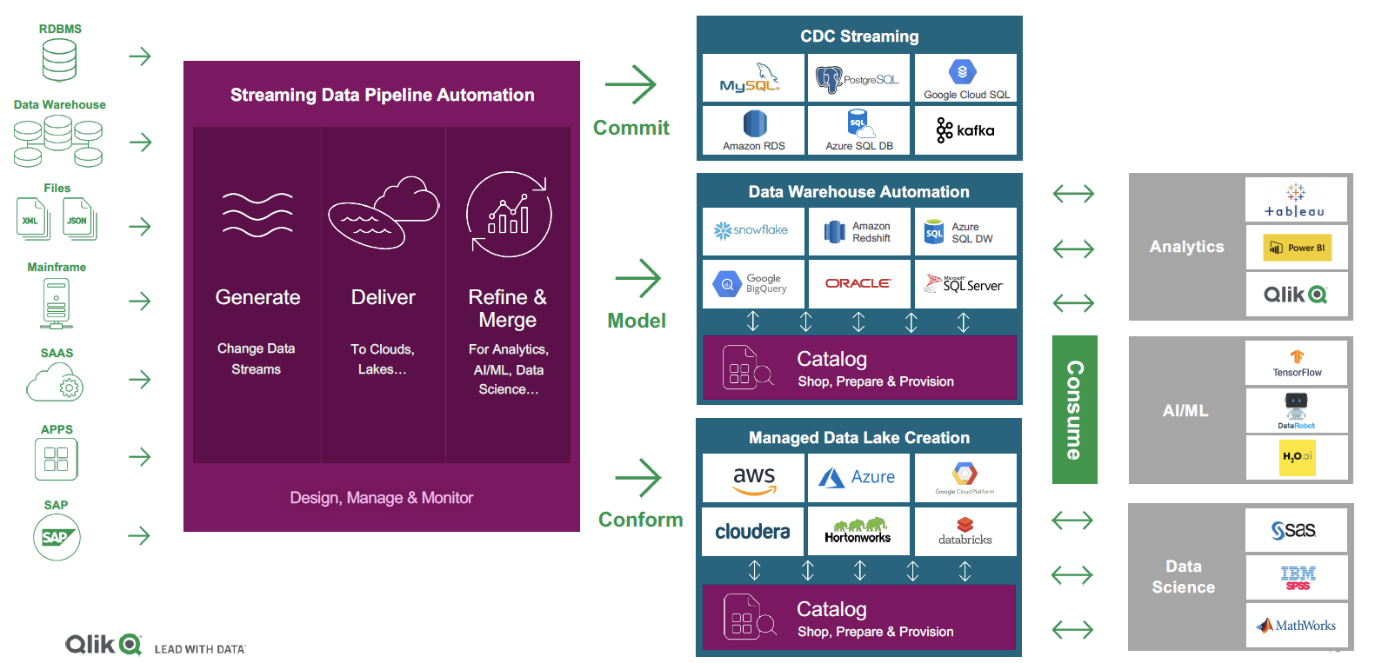
Fig 02 - Qlik Data Integration Platform components
As far as the actual details are concerned the overall architecture is illustrated in Figure 2. Starting with Qlik Replicate provides automated data delivery, replication, and ingestion from more than 40 sources and around 35 targets are supported, data warehouses, data lakes (including S3 and other object stores), mainframe and the cloud. Additional features include a modern, drag and drop user interface; zero performance footprint on data sources; and log-based CDC, the ability to capture changes to data sources in real-time. The product feeds source metadata updates to Compose-managed data lake and data warehouse targets on a real-time basis. As can be seen in Figure 2 there are two distinct versions of Compose: Compose for Data Warehouses and Compose for Data Lakes. In both cases, they are designed to automatically create analytics-ready data structures for their respective targets, and they may be used separately or together. When used in conjunction, this allows you to store data in a data lake before exposing it via data marts.
In addition, Qlik also offers Qlik Enterprise Manager, which offers automated task and data flow management as well as reporting and performance monitoring, integrating, and sharing metadata across heterogeneous environments that include Compose-enabled data pipelines.
As far as Qlik Catalog is concerned data and metadata are tightly coupled and this supports not just a searchable data catalogue but also a business glossary. Profiling and validation processes are automated during the ingestion process of data. While the product currently lacks the ability to make automated recommendations (this is on the roadmap) – identifying such things as potential join keys – the processing during ingestion will identify primary and foreign keys, duplicates and so forth. It also categorises data as good, bad, or ugly, where bad and ugly differentiate between formatting errors and outliers. There is also support for crowd sourcing within the product’s data curation process. The product’s support for security, privacy and access control is a major strength as its support for data masking, with more than thirty different masking algorithms supported. Data stewardship capability allows you to define and enforce governance policies.