
IBM
Last Updated:
Analyst Coverage: Philip Howard, Fran Howarth, David Norfolk, Daniel Howard and David Terrar
IBM is a multinational technology and consulting corporation, with headquarters in New York but a global presence. IBM manufactures and markets computer hardware and software, and offers infrastructure, hosting and consulting services in areas ranging from mainframe computers to nanotechnology. The company was founded in 1911 and over the years has grown through acquisition into its present state.
IBM initially made its profits largely from selling hardware, but these days it is more of a software solutions and services company. It currently stresses the delivery, from smarter computing, technology and process, of better business outcomes for the smarter planet. IBM has initiated various emerging open standards and open environment initiatives (such as Eclipse, Jazz, OSLC, RELM and so on) and owns many significant brands such as DB2 Universal Database, WebSphere, Watson and System z.
IBM Cloud
Last Updated: 10th July 2023
Mutable Award: Gold 2023
With more than half and eye on the growing complexity of not just existing cloud service environments but the extension that edge computing will being to them, IBM does look to be focusing on offering customers strong ‘how to’ hand-holding services to existing and new customers when it comes to adopting edge computing.
According to IBM, it has seen the core shift that is now happening as being a change from the mobile internet era to a world of hyper-connectivity, an evolution it sees being accelerated by demand from enterprise users for greater digital transformation. The mobile internet era was about mobile connection to internet and simply consuming content. The hyper-connected era is about digital intersecting with every aspect of its customers business operations and, through them, everyone’s physical lives.
It is about providing a cloud service capability that mimics the physical interactions that we have every day by using digital solutions. IBM sees this inevitably leading to new ecosystems and partnerships that bring all these different aspects of technology, business and services together in order to drive and exploit the levels of hyper-connectivity now available.
The starting point of the ‘how to’ hand-holding operations is the company’s methodology called Garage. This brings together a small group of domain experts from the customer company, the service providers and a sponsor from the IBM line of business, to work together over a two-to-three-month period to learn how to develop new services and applications by working through well-targeted examples.
The goal is to produce the minimum viable, deployable service that can be delivered to stand alone at the end of that period, before moving on. The collected results of this process will be able to work together across both the edge and data center as different parts of exactly the same Software Defined Network.
Quotes
“The hyper-connected era is about digital intersecting with every aspect of its customers business operations and, through them, everyone’s physical lives.”
“The important aspect here is that IBM Cloud comes with the expertise and experience of working with both its own edge related capabilities but also with other specialist technology and knowledge providers.”
The key factor is that the edge and the cloud share a lot in common in terms of development practices, containerisation, separation, loose coupling, continuous integration and delivery processes, DevOps, and Agile development practices. However, there are also fundamental differences, particularly because the edge tends to be much more diverse, with much more variation in the underlying compute architecture, configurations, purpose, and locations where edge computing is being performed. Edge services are much more dynamic and changeable, with systems reconfiguring
and changing purpose. In short, according to the company, it is at least an order of magnitude more complex.
Also, unlike the cloud where one is dealing with a few variations on the Intel x/86 processor architecture, the edge consists of a far wider variety of devices. Increasingly, they are also all going to be connected and come with enough memory and CPU power to conduct at least a small amount of in-situ processing, even if that is not required at the moment. The challenge here, therefore, is achieving a usable level of integration between such disparate devices. To help customers achieve this, IBM Cloud has already formed a partnership with Mimik Technology.
The company is therefore pitching its cloud services capabilities as the underlying tool with which to build and deliver these capabilities, the Software Defined Networking capabilities that can reach down to the widest, farthest and smallest corners of a company’s overall network architecture and up to the highest levels of business management. This capability can therefore be delivered by IBM in its entirely, as the sole provider of all aspects of the cloud service, or the company can deliver part of an overall, hybrid solution where, for example, the edge computing capabilities are an additional service to network topology a customer is already using.
The important aspect here is that IBM Cloud comes with the expertise and experience of working with both its own edge related capabilities but also with other specialist technology and knowledge providers. It can, therefore provide new customers with a space in which they can experiment with small-scale edge computing developments that not only provide learning for a customer’s development teams but also a working service that can provide observable benefits.
It is easy to assume that a cloud service is a cloud service is a cloud service, and at first look that can be a reasonable assumption, especially when it comes to businesses that have no requirement to `push the envelope’ of operations requirements in any direction at all. Look deeper, however and differences in service provisions and capabilities may prove to be vital. For example, not all will be able to work effectively in an edge computing environment. They will be able to work with such a service, not provide it satisfactorily.
Edge computing is still very much in its early developmental stages, and it has to be observed that it is already one of the new phrases in the lexicon of technology vendor marketing personnel. There are increasing examples of such vendors now talking up their ‘edge-capable’ credentials, quite often with little direct evidence that established, even legacy, products are entirely suitable for the work a user may be hoping they will match. Without experience and prior knowledge it becomes far too easy for new users to trap themselves down unsuitable, often blind alleys, and then press onward in the hope that the investments already made will somehow bear fruit.
With that in mind the experience and expertise that underpins IBM Cloud, which includes that generated by many years of developing and running major industrial and commercial projects with IBM Global Services. Having that now available to those businesses looking to extend into edge computing, offers an opportunity to fast-track that development process, and bypass the many pitfalls that might otherwise entrap them.
Mutable Award: Gold 2023
IBM Cloud Pak for Data
Last Updated: 3rd March 2021
Mutable Award: Gold 2021

Fig 01 - IBM Cloud Pak for Data high-level architecture
IBM Cloud Pak for Data is a cloud-native (microservices, Kubernetes and so forth) data management platform that places particular emphasis on deploying, developing and managing AI and machine learning models but also encompasses more general-purpose data management. The platform consists of a large number of IBM services (some of which are included as part of the base product, while others must be licensed separately) that integrate together and are accessible through a singular interface. It can be deployed to the most popular public clouds – AWS, Microsoft Azure, and Google Cloud – as well as to IBM Cloud and to hyper-converged systems. In addition, it features an open architecture built on Red Hat OpenShift, which is shown in Figure 1.
This is a slightly misleading diagram since although it mentions event ingestion and data transformation there is no mention of traditional data integration capabilities, which are provided via InfoSphere DataStage for Cloud Pak for Data. Similarly, although there is mention of data quality and classification, and of policies and rules, there is no mention of data governance, compliance or how to discover and manage sensitive data, even though these are all available with, for example, Watson Knowledge Catalog providing data masking capabilities. Again, while data cataloguing is mentioned metadata management is not, despite IBM being a major driver behind the open source ODPi Egeria project.
More generally, the services offered by the Cloud Pak for Data range across a number of spaces, including analytics (in a variety of types, such as prescriptive, predictive, streaming, big data and so on), databases and data warehousing, dashboarding, data virtualisation, data integration, data cataloguing, data governance, and, of course, AI and machine learning. Particularly notable products and services include Cognos Analytics, IBM’s premiere self-service analytics and business intelligence platform; Watson Machine Learning, Watson Studio and Watson Knowledge Studio, all of which support model creation, training, deployment and management in one way or another; Watson OpenScale, which adds bias detection and model explainability to the platform’s AI capabilities; Watson Knowledge Catalog, for data governance and cataloguing; InfoSphere DataStage, for ETL and data integration; and several use case specific AI products, such as Watson Assistant for conversational AI, Watson Discovery for AI-enabled enterprise search, Watson Language Translator for AI-driven translation, and so on. Note that these are the headline products: a large number of less glamorous – though not necessarily less useful – services are also provided, such as databases (Db2, Db2 Event Store, Netezza), developer tools and product integrations.
Customer Quotes
“IBM Cloud Pak for Data enabled Sprint to digest high volumes of data for near, real-time ML/AI analysis, and the trial results have shown potential to take Sprint to the next phase of digital transformation.”
Sprint
“One of the great things about the Cloud Pak for Data System is the speed with which we’ll be able to launch and scale our analytics platform. The integrated stack contains what we need to improve data quality, catalog our data assets, enable data collaboration, and build/operationalize data sciences. We’re able to move quickly with design, test, build and deployment of new models and analytical applications.”
Associated Bank
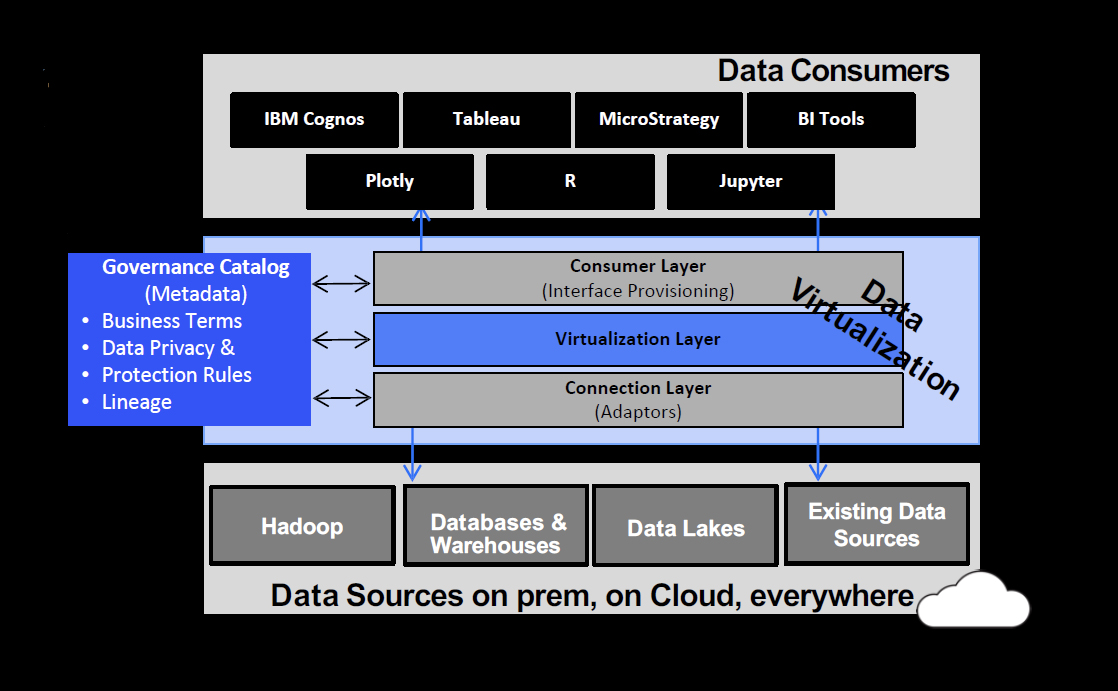
Fig 02 - IBM Cloud Pak for Data governed data virtualisation
Cloud Pak for Data offers a single, unified platform for in-cloud data management that is itself built around a single, unified data catalogue: namely, Watson Knowledge Catalog. This setup is in turn supported by a robust layer of governed data virtualisation, as seen in Figure 2, and powered by the appropriately named Data Virtualization. Data Virtualization layers what IBM describes as a computational mesh (which is automated, self-balancing, and scalable) over your data sources. This is, in our opinion, the most advanced technology for data virtualisation currently available on the market. Importantly, Data Virtualization is in constant communication with the Watson Knowledge Catalog, and in many ways enables it to act as it does, as a unified repository for all of your data. Creating a unified view of all of your data in a single location has obvious advantages, but for the purposes of Cloud Pak for Data, one of the most notable is that it makes it much easier to leverage the full range of your data within your AI models.
On the subject of AI, note that a number of pre-built AI apps are available within several Cloud Pak for Data services. Also note that one of the major (and most time consuming) difficulties in developing your AI models comes from discovering, understanding, and preparing the data that they rely on. With this in mind, Cloud Pak for Data has a significant DataOps capability that adds automation to your data pipelines. This should increase the speed of those pipelines and thus shorten the process of delivering that data, ultimately enabling more efficient model development. Automation is not only present within the data preparation step, however. To wit, Watson Studio also offers AutoAI, a feature that actively and intelligently automates the model creation process itself: IBM describes this as “AI automating AI”.
The enforcement of governance rules and policies can be automated as well, via Watson Knowledge Catalog. Not only that, but bodies of knowledge provided by both your organisation and by IBM can be baked into your catalogue, thus centralising and exposing your own tribal expertise as well as broader industry and regulatory knowledge, most notably compliance mandates such as GDPR and CCPA. Watson Knowledge Catalog also features automated profiling and classification, as well as AI-driven tagging recommendations.
The major reason to care about Cloud Pak for Data is that it offers a broad swathe of data management functionality within a single, unified platform. Offering an end-to-end and interoperable data management stack, while not unique to Cloud Pak for Data, is a significant advantage that serves to distinguish it from many other data management vendors. In addition, Cloud Pak enables a gradual, at your own pace, pathway to migrate from an on-premises environment to a multi and/or hybrid cloud environment.
The Bottom Line
IBM Cloud Pak for Data is a broad, cloud-native, and highly integrated and interoperable data management platform which is particularly good at enabling your own AI and machine learning efforts.
Mutable Award: Gold 2021

IBM Db2 Event Store
Last Updated: 1st July 2020
Mutable Award: Gold 2020
Db2 Event Store is a database that is packaged within IBM Cloud Pak for Data, though it is also available stand-alone. Briefly, IBM Cloud Pak for Data is an integrated data science, data engineering and app building platform built on top of the Red Hat OpenShift Container Platform. The intention is to a) provide all the benefits of cloud computing but inside your firewall and b) provide a stepping-stone, should you want one, to broader (public) cloud deployments. It has a micro-services architecture and provides an environment that will make it easier to implement data-driven processes and operations and, more particularly, to support both the development of AI and machine learning capabilities, and their deployment.
As far as Db2 Event Store is concerned, it is intended to support both near real-time and deep analytics on historic data. And, when combined with IBM Streams, they support the whole gamut of analytics requirements. Typical applications include anti-fraud, smarter manufacturing, and advanced data modelling on real-time data flows, amongst others. Effectively, what Db2 Event Store enables is a solution that replaces a so-called Lambda architecture, which is an approach that involves using multiple databases. This is complex and requires at least two different development environments. An alternative is a Kappa architecture that uses a single persistent store but, typically, Kappa architectures do not support the sort of deep analytics needed to support machine learning and AI. Db2 Event Store, on the other hand, has been designed to provide a single environment that supports all of the requirements outlined, enabled, at least in part, by the common SQL engine.
Db2 Event Store is built on top of the Apache Spark platform (including support for Spark geospatial and time-series functions) and provides an in-memory database that stores data in Parquet format. However, it uses the Db2 optimiser (and also some elements of Db2 BLU technology) rather than the standard Spark optimiser, as the former is more efficient. Storage is separated from compute to allow independent scaling.
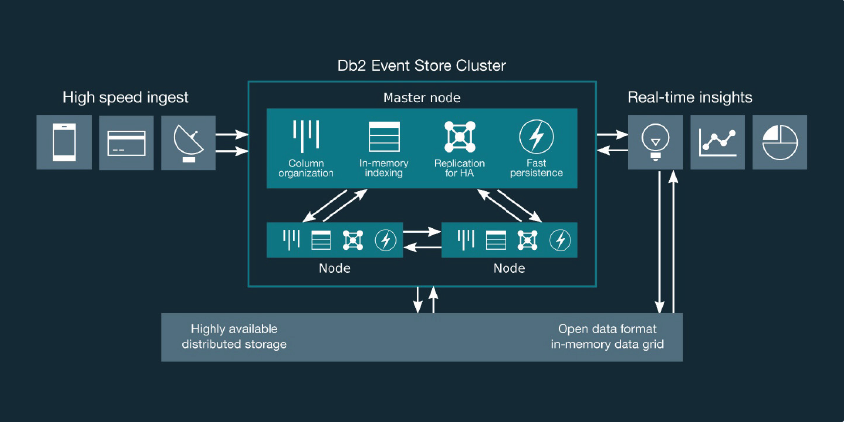
Figure 1 - Architecture of IBM Db2 Event Store
The architecture of the product is illustrated in Figure 1. The two main issues will be on performance for ingest and persistence on the one hand, and performance for query processing on the other. In the case of the former, the log is the database. This means that the amount of synchronous processing required is minimised, with other processes occurring asynchronously. The first of these asynchronous (background) steps is to remove any duplicates and this is followed by generating a synopsis (used for range queries) and indexes. After this the data is transformed into Parquet format and compressed. However, this results in multiple small files, which would be inefficient in supporting query processing, so a merge function is used to combine these into larger files. According to IBM these background processes typically take under a minute from ingest to persistence but the company is hoping to reduce this to a matter of seconds in forthcoming releases.
As far as query processing is concerned, a lot of the performance offered by Db2 Event Store is based on the features already mentioned, including the synopses, indexes and in-memory processing. Parallel processing and tiered caching (including CPU caching, a feature of Db2 BLU) also support superior performance, as does use of the Db2 Optimiser. A notable feature of this, planned for release later in 2020, is that IBM is introducing machine learning into the optimiser in order to improve query planning. This is already available as an optional feature within other members of the Db2 family.
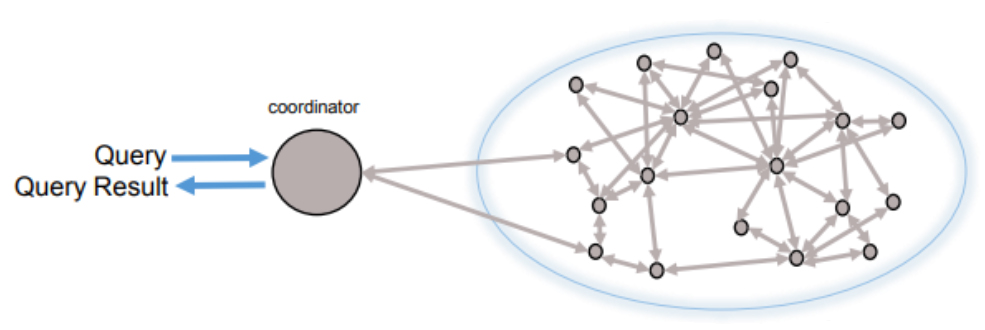
Figure 2 - IBM Data Virtualization Computational Mesh
Apart from its integration with IBM Streams, Db2 Event Store will also benefit from the Data Virtualization capability within IBM Cloud Pak for Data. This is both innovative and ahead of other offerings in the market. The key difference from traditional approaches to data federation/virtualisation is that IBM uses a computational mesh – see Figure 2 – that not only performs analytics locally but also within a local constellation. Given that moving the data across the network is the biggest issue with traditional data federation techniques this should significantly improve performance. Moreover, this should have a significant impact on costs because you need less infrastructure to get the same (or better) performance. Data sources supported by the computational mesh include the Db2 family, Netezza, BigSQL, Informix, Derby, Oracle, SQL Server, MySQL, PostgreSQL, Hive, Impala, Excel, CSV and text files, MongoDB, SAP HANA, SAS, MariaDB, CouchDB, Cloudant, various Amazon and Azure databases, sundry streaming products (including Kafka), multiple mainframe environments (IBM and others), generic JDBC access and several third-party data warehousing databases. Note that Data Virtualization integrates with the Enterprise Data Catalog, which also forms part of IBM Cloud Pak for Data.
There have been various attempts to combine the analysis of both (near) real-time and historical data within a single environment and, as we have discussed, Db2 Event Store provides a much less complex solution to this issue compared to other available approaches. More generally, the implementation of Db2 Event Store along with IBM Cloud Pak for Data brings multiple benefits, not least the data virtualisation provided. We also particularly like the fact that there is a common SQL engine across the Db2 family. Moreover, this is ANSI 2016 compliant compared to other vendors that are sometimes still working with versions of SQL from the last century!
The Bottom Line
We like Db2 Event Store a lot. If you want to combine up-to-the-moment data with historical data for analysis purposes, it should certainly be on your short list. As part of IBM Cloud Pak for Data, the complementary capabilities provided therein, make the offering compelling.
Mutable Award: Gold 2020

IBM Doors
Last Updated: 28th May 2013
Doors is an industrial-strength (expensive) requirements management tool which IBM acquired when it bought Telelogic. The original version of Doors focused more on storing and managing requirements than on visualising them, modelling them and so on; it was particularly suited to formal Systems Engineering and to building systems which needed formal compliance to standards etc - it had strong reporting capabilities. Nevertheless, older versions of Doors had limited (view only) web access functionality and poor integration with Microsoft Office.
However, Doors now ships with Doors Next Generation (Doors NG), which addresses many of the perceived limitations of Doors without compromising its strengths and Doors Web Access addresses that issue. Doors NG works with traditional Doors (using OSLC specifications) and comes with Doors. It adds collaboration capabilities for multi-disciplinary product development teams and a lighter-weight Requirements process (suitable, perhaps, for teams migrating from Requirements stored in documents and spreadsheets to something more effective). It provides full web-based access together with an optional rich client on the Microsoft platform. Doors NG is probably a sign of where Doors is going, towards a tool with full configuration management built in, so that different teams can work on different versions of, essentially, the same requirements at once; and local or market-specific versions of common requirements can be maintained.
Doors is bought through normal IBM channels. Doors NG is supplied with Doors, if you buy the latest Doors release. A trial version is available.
Doors is targeted particularly at (but not limited to) Systems Engineering professionals, working on high-value, regulated or safety-critical systems; defense, aerospace, health, transport and so on
Doors is a client/server application with its own database and its back-end runs on a range of Windows. UNIX and Linux servers.
IBM offers all the services, available across the globe, that one might expect to need in support of this product.
Particularly noteworthy is the OSLC community. OSLC or Open Services for Lifecycle Collaboration, is a set of interface specifications which allows Doors to produce/consume services with, say, Rational Team Concert (an Agile application lifecycle management (ALM) solution) or, potentially, other tools supporting OSLC.
Doors is a market leader in the formal requirements management space, so (allowing for the fact that not every developer is skilled ior experienced with using requirements management), it should not be hard to find Doors expertise. IBM supplies Door consultancy and training courses, both in the classroom and online (video); and a range of external trainers and consultants are also available to facilitate deployment of Doors in the organisation (although always remember that institutionalising reequirements management is as much a cultural/people issue as a technology one).
IBM Informix
Last Updated: 28th February 2020
Mutable Award: Platinum 2019
IBM Informix is an object-relational database with native support for both time-series and geo-spatial data. After its acquisition of Illustra in the mid-1990s its initial focus was on irregular time-series as generated within capital markets (stock ticks). It subsequently extended this to support regular time-series of the type that might derive from sensors. In 2015 the product was extended – leveraging its existing geo-spatial capabilities – to support spatiotemporal queries for moving objects and, even more recently, support for high frequency (sub-second) time-series, sometimes known as Hertz data, has been added.
The product is positioned as a database for Internet of Things (IoT) environments and highly distributed applications. It has a small enough footprint (it will run on a Raspberry Pi Zero, though preferably a Pi2 or later), together with fire-and-forget functionality, to make it practical to deploy at the edge. Conversely, it is equally capable of running in mainframe environments. The product is also suitable for – and there are clients using it for – environments where the emphasis is on monitoring and metrics rather than analytics.
Customer Quotes
“We were looking for an enterprise-class database that was truly tailored for use in an IoT environment, and IBM Informix fit the bill perfectly. With Informix, we get excellent scalability and strong security, and can manage both structured and unstructured data effectively. What’s more, the platform has a very small footprint, making it ideal as an embedded database.”
Petrosoft
“We estimate that using Informix works out at around a tenth of the cost of a traditional relational database, and the time saved enables us to cut our time-to-market for new services.”
Hildebrand
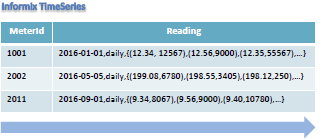
Fig 01 Support for native time-series datatype
Informix supports a native TimeSeries datatype with relevant data stored as illustrated in Figure 1. Note that this is much more efficient than would otherwise be the case for a relational database, which would typically have multiple rows for each Meterid: one for each time stamp. Compared to Informix’s approach, which does not require indexes, a relational storage model would require these on the meterID (or more), thereby adding significant overhead to the storage model. Specialised compression capabilities are provided. In addition, if it is a regular time-series Informix allows you to skip the storage of the time stamps altogether. If readings are static – subject to intervals you define – you can compress the results or filter them out. A variety of windowing data analytics functions – moving, static, rolling and so on – are provided.
Ingestion is via the Informix TimeSeries Loader, which is parallelised to ensure high performance.
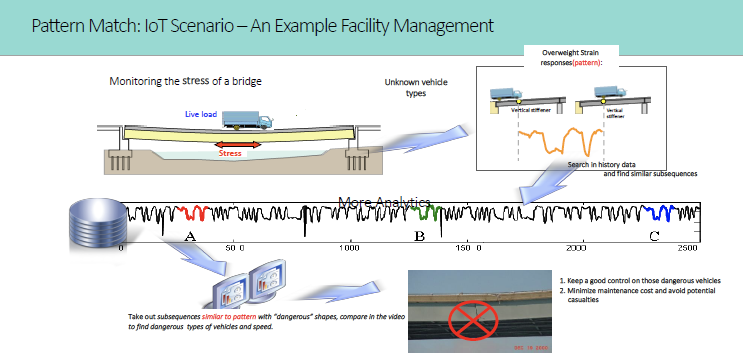
Fig 02 Example of pattern matching
You can access TimeSeries data using SQL (for which there are more than 100 pre-defined functions), either via a virtual table interface, which makes the time-series data look relational; or you can create user-defined routines (UDRs) using stored procedures. C (for which further functions are provided) is also available, as is Java. These UDRs are registered with the database optimiser and used for query and other CRUD purposes. While HCL/IBM do not have partnerships with any third party visualisation vendors, there are users employing tools such as Grafana and Tableau (via ODBC/JDBC connectivity) together with Informix time-series. Of course, the product integrates with IBM Cognos. Sophisticated analytics, such as pattern matching, are available, as shown in Figure 2, though there is no facility to discover patterns in the first place. There are specific TimeSeries API capabilities to support anomaly detection and other advanced analytics.
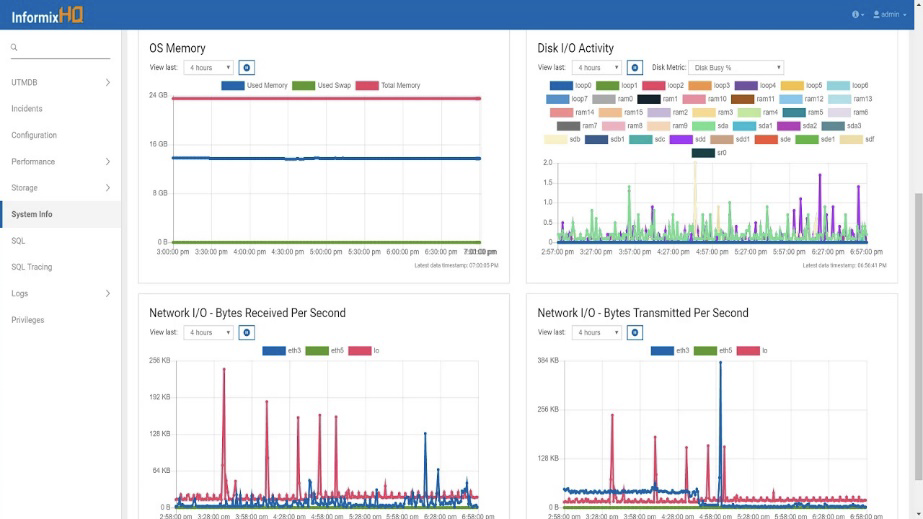
Fig 03 InformixHQ
Geo-spatial capabilities represent an important complement to time-series in many IoT environments and Informix supports around 20 different co-ordinate systems with built-in indexing and native support for spatial datatypes. There is tight integration with ESRI and support for GeoJSON. It is also worth commenting on the utility of the spatiotemporal capabilities provided by Informix. These are not limited to traditional logistics examples, but also allow you to answer questions like “what was the location of bus number 3435 at 2019-03-01 15:30?”, “when was a delivery truck within 100 meters of the Good Food Diner between February 2-4, 2019?”, “when was taxi number 324 at the Superlative Hotel?”, “how long do buses stay in our repair shop?”, or “which taxi driver witnessed an accident by finding which taxi was nearest to the location of the accident at 9:00 am?”.
Finally, it is worth mentioning InformixHQ, which is illustrated in Figure 3. This is a monitoring and administration tool that has been developed for the Informix environment itself. However, it does have features that will allow you to construct your own dashboards, though these probably need further development before the product will be suitable to support monitoring of third-party environments.
Databases that offer time-series capabilities come in a wide range of shapes and sizes. Some are purely focused on analytics and/or monitoring, while others – including Informix – support both analytics and operational uses cases, as well as hybrid requirements that need both. Then again, many products other than Informix that support time-series have limited, if any, geo-spatial capabilities, which means they simply are not suitable for many IoT applications. Moreover, Informix is unique, as far as we know, in offering spatiotemporal search.
The Bottom Line
Informix has been offering TimeSeries and geo-spatial data longer than any other database on the market. In many cases for longer than competitive offerings have been in existence. The experience that comes with this longevity is clear in the depth and breadth of the capabilities offered.
Mutable Award: Platinum 2019

IBM Informix Warehouse Accelerator
Last Updated: 6th May 2013
IBM offers various editions of Informix that are based on the Informix Warehouse Accelerator. This is an extension to the normal database used for transactional purposes. Typically, the Warehouse Accelerator will be implemented on the same system as the relevant transactional environment with analytic data processed in its own memory space so that there is on conflict with operational aspects of the environment - transactional performance should not be impacted.
A major feature of Informix is that it natively supports time series, which both minimises space when you need to store data with time stamps and improves performance. We should state that we know of no other transactional database that has this support. Also pertinent is that Informix has native geospatial capabilities.
Informix has been focused on the VAR and ISV market by IBM and the Warehouse Accelerator will allow partners to extend their existing applications built on top of Informix and to introduce new operational analytic capabilities for their clients. In terms of direct sales, however, IBM is targeting smart metering (and therefore utilities and energy companies) with the Informix Warehouse Editions. This application has both operational and analytic requirements. In the former case, for example, you need to recognise outages and handle them in a timely manner, while in the latter case you need analytics for planning purposes (for example, at what times of day do we need to ramp up power production), marketing (what incentives can we provide for more efficient use of resources) and fraud detection, to quote just some examples.
The company targets telecommunications, public sector and retail as sectors in addition to smart metering. It is also examining which markets might be most suitable to use Informix's geospatial capabilities both as a stand-alone feature and in conjunction with time stamps.
While Informix has customers numbered in the tens of thousands and there are many Informix customer references on the IBM web site (the most recent being Cisco) these are predominantly for Informix per se rather than the Warehouse Accelerator and those that we do know of in this category do not want their names publicised.
The Informix Warehouse Accelerator enables dynamic query processing in-memory; together with parallel vector processing and advanced compression techniques; along with a column-based approach to avoid any requirement for indexes, temporary space, summary tables or partitions. In other words it is entirely suitable for supporting analytic applications because the lack of the features mentioned means that administration is both minimised and consistent across transactional and analytic environments.
Typically, the Warehouse Accelerator will be implemented on the same system as the relevant transactional environment. When this is the case you use Smart Analytics Studio, which is a graphical development tool, to define the data (and its schema) that you want to query and the Warehouse Accelerator will automatically offload this data, which is now stored separately from the OLTP environment. It is processed in its own memory space so that there is no conflict with the operational aspects of the environment and transactional performance will not be impacted. Note that there is no need to change your existing business intelligence tool(s).
The optimiser has been specifically designed to support both transactional and analytic workloads when a hybrid environment is being deployed. The optimiser knows what data is in the data mart and what is not: it will determine whether the query can be satisfied by the Accelerator and, if so, it routes the query there. If not, it will choose to execute the query within Informix. Now, if a query saves the result into a temporary table as part of the Select statement, as is often done by certain BI tools, then the Accelerator can speed up that portion of the query.
The smart metering market, at which the Informix Warehouse Editions are mainly aimed, is still in its very early stages. However, whether it is for smart metering or not the ability that Informix offers, to perform serious analytics on the same platform as transactional functions, is a strong one. The way that the system has been designed is not simply as one system for two different functions - which we do not regard as ideal - but, effectively, as two different systems on the same box and with the same administration; both linked by some clever software and purpose-built optimiser functions. Thus from a theoretical point of view, Informix has every chance of success within its target market. The danger is that while IBM has recently ramped up its development and marketing of Informix, this may not last if returns are not seen in the short to medium term. Informix is very much IBM's third database, after DB2 and Netezza, and it is important that momentum is maintained.
In addition to the normal sorts of training and support services you would expect from any vendor, IBM offers business services (application innovation, business analytics, business strategy, functional expertise, midmarket expertise), IT services (application management, business continuity and resiliency, data centres, integrated communications, IT strategy and architecture, security), outsourcing services (business process outsourcing and IT outsourcing and hosting), asset recovery, hardware and software financing, IT lifecycle financing and commercial financing.
IBM InfoSphere Discovery
Last Updated: 8th May 2013
IBM InfoSphere Discovery was previously known as Exeros before the company known with the same name was acquired by IBM. It is a data profiling and discovery tool. While it has always been technically a part of the InfoSphere portfolio it was originally marketed along with the company's Optim solution to support data archival, masking and similar functions. However, there is another InfoSphere product that also offers data profiling, known as Information Analyzer. In our view Discovery is much the superior product (because it offers extended discovery capabilities) for processes such as data migration and in supporting master data management (MDM) initiatives. IBM needs to make clear that Information Analyzer is really only suitable in data quality environments where it is simply a question of profiling individual data sources and there is no requirement for cross-source analysis.
Major elements in the Discovery platform are the Discovery Engine and Discovery Studio. The former is the component (or components - you may have multiple engines for scalability purposes) that does the actual process of discovering business rule transformations, data relationships, data inconsistencies and errors, and so on. Where appropriate it generates cross-reference tables that are used within the staging database, it creates metadata reports either in HTML format or Excel, and it generates appropriate SQL, XML (for use with Exeros XML) and ETL scripts (for use in data migration and similar projects). Discovery Studio, on the other hand, is the graphical user interface employed by data analysts or stewards to view the information (both data and metadata - Discovery works at both levels) discovered by the engine; and to edit, test and approve (via guided analysis capabilities) relationships and mappings from a business perspective.
InfoSphere Discovery is an enabling tool rather than a solution in its own right so it is horizontally applicable across all sectors. It will be particularly useful where it is necessary to understand business entities (for example, a customer with his orders, delivery addresses, service history and so on) and process those business entities as a whole. Notable environments that require such an approach include application and database-centric data migrations, master data management and archival.
We have no doubt that IBM has many successful users of InfoSphere Discovery. However, you wouldn't know that to judge by its web site, which includes just two case studies where customers are using the product - CSX and FiServ - but in neither paper is the use of InfoSphere Discovery discussed; the product is simply listed as one of the IBM products in use.
In addition to providing conventional data profiling capabilities (finding and monitoring data quality issues) Discovery supports the discovery of orphaned rows, scalar relationships (simple mappings, substrings, concatenations and the like), arithmetic relationships between columns, relationships based on inner and outer joins, and correlations for which cross-reference tables are generated. Cross-source data analysis is available both to discover attribute supersets and subsets, and to identify overlapping and unique attributes. In the latter case there is a visual comparison capability that allows you to compare record values from two different sources on a side-by-side basis. In addition there are automatically generated source rationalisation reports that compare data sources to one another. Further features include support for filtering, aggregations and if-then-else logic, amongst others.
There is also a Unified Schema Builder designed specifically to support new master data management, data warehousing and similar implementations that includes precedence discovery, and empty target modelling and prototyping. There are also facilities for cross-source data preview, automated discovery of matching keys (that is, a cross-source key for joining data across sources), automated discovery of business rules and transformations across two or more data sets with statistical validation, and automated discovery of exceptions to the discovered business rules and transformations.
This is what we wrote in our 2012 Market Report on Data Profiling and Discovery: "since our last report into this market IBM has acquired Exeros, which was market leading for discovery purposes at that time. It should therefore come as no surprise that IBM offers the best understanding of relationships of any product that we have examined. For pure profiling capabilities IBM InfoSphere Discovery is good without being outstanding but it is clearly one of the market leaders when discovery is required alongside profiling." That view remains unchanged: in support of MDM, migration, archival and similar environments Discovery is clearly the leading product in the market.
In addition to the normal sorts of training and support services you would expect from any vendor, IBM offers business services (application innovation, business analytics, business strategy, functional expertise, mid-market expertise), IT services (application management, business continuity and resiliency, data centres, integrated communications, IT strategy and architecture, security), outsourcing services (business process outsourcing and IT outsourcing and hosting), asset recovery, hardware and software financing, IT lifecycle financing and commercial financing.

IBM InfoSphere Optim Test Data Management
Last Updated: 20th June 2014
Test Data Management (TDM) is about the provisioning of data for non-production environments, especially for test purposes but also for development, training, quality assurance, demonstrations or other activities. Historically, the predominant technique for provisioning test data has been copying some production data or cloning entire production databases. Copying 'some' of the data has issues with ensuring that the data copied is representative of the database as a whole, while cloning entire databases is either expensive (if each team has its own copy) or results in contention (if different teams share the same copies). The other major problem with these approaches is that because of cost/contention issues the environments are not agile and you need agile test data to complement agile development.
IBM InfoSphere Optim Test Data Management resolves these issues, and supports a DevOps-based approach, by allowing you to create referentially intact subsets of the database that accurately reflect the structure of the original data source. This is important because you want test data to be representative of the live environment, as otherwise important test cases can be missed. In the case of IBM InfoSphere Test Data Management, subsets may be of different sizes for different testing purposes: for example, you might want a larger test database for stress testing than for some other types of tests.
There are, in fact, two versions of IBM InfoSphere Optim Test Management: one for z/OS and one for other systems. The latter is currently in version 9.3
IBM InfoSphere Optim Test Data Management is horizontally applicable across all sectors and is marketed directly by IBM. It is particularly useful in DevOps environments where development and operations are collaborating with one another and it also especially complements agile development methodologies.
IBM also has partners marketing specific solutions based on IBM InfoSphere Optim Test Data Management. For example, TouchWorld offers a solution for test data for SAP applications.
IBM’s InfoSphere Optim Test Data Management Solution has a global client base with over a thousand clients worldwide across a variety of industries. DevOps and the need for Continuous Testing are currently driving more demand for an effective test data management solution. Data masking for non-production environments is another requirement creating demand. Customers using IBM Optim Test Data Management include Nationwide Insurance, Conway Inc., GEICO, CSX Corporation, Allianz Seguros, Cetelem (part of BNP Paribas), Dignity Health and HM Land Registry.
IBM's InfoSphere Test Data Management solution provides capabilities to: discover and understand test data, discover sensitive data, subset data from production, mask test data, refresh test data and analyse test data results. This integrates with the IBM Rational Test Workbench as well as other leading testing suites such as HP Quality Center. You can also use the IBM Rational Service Virtualisation Product (previously Greenhat) and IBM’s Rational Urbancode Deploy in conjunction with this offering. This service virtualisation is important when (some) test data is derived from external sources or is otherwise not easily available.
Notable features of IBM InfoSphere Optim Test Data Management include a range of data masking options, very advanced discovery capabilities, a data comparison capability, data sub-setting based on an understanding of data relationships (to ensure that test data is representative) and support for multi-sized data subsets. InfoSphere Optim Test Data Management can generate a completely anonymous set of data, but this requires a specification of the original data set, which can be a barrier for some clients. Note that this differs from synthetic generation that is generated from a profile of the data, as opposed to being generated from a base dataset. It is likely that IBM will introduce synthetic generation at some point in the future.
There are actually three phases to deployment of IBM InfoSphere Optim Test Data Management: move, edit and compare. In the move phase you extract, copy and move the data (which may come from multiple sources) not necessarily just for creating test data but also to support data migration and data ageing. In the edit phase you can view, and edit if necessary, the extracted data, which can be in any arbitrarily complex schema. In the compare phase you can compare data from one set of source tables with another either online in the Optim GUI or in reports. Compare enables automated comparison of two sets of data, then enables users to do things like compare data after a test run with the baseline 'before version' or track database changes or compare different data sources. The three phases, deployed together, enable organisations to easily conduct iterative testing, for faster and more comprehensive testing.
The product runs on Windows, Linux and UNIX platforms and supports not just IBM’s own database products (DB2, Informix et al) but also leading third party database products such as Oracle, SQL Server and Teradata.
In addition to the normal sorts of training and support services you would expect from any vendor (which includes extensive online resources), IBM offers business services (application innovation, business analytics, business strategy, functional expertise, mid-market expertise), IT services (application management, business continuity and resiliency, data centres, integrated communications, IT strategy and architecture, security), outsourcing services (business process out-sourcing and IT outsourcing and hosting), asset recovery, hardware and software financing, IT lifecycle financing and commercial financing.
IBM InfoSphere Streams
Last Updated: 30th May 2014
IBM InfoSphere Streams is a high performance, low latency platform for analysing and scoring data in real-time. Environments where InfoSphere Streams might be deployed range from relatively small implementations on a single laptop to multi-node implementations scaling to hundreds of thousands or millions of transactions per second. Typical use cases involve looking for patterns of activity (such as fraud), or exceptions to expected patterns (data breaches) or to find meaningful information out of what otherwise might be considered noise (six sigma), as well as commercial applications such as analysing how customers are using their cell phones (in conjunction with IBM’s recent acquisition The Now Factory). In other words, InfoSphere Streams is essentially a query platform.
In addition to working in conjunction with The Now Factory, InfoSphere Streams also integrates with other IBM products including SPSS (for building predictive models that you can score against in real-time), QRadar (for security information and event management: SIEM) along with BigInsights, external visualisation tools (including Watson Explorer) and data integration environments.
In addition to the main InfoSphere Streams product (currently in version 3.2.1) IBM also offers a Quick Start Edition that is available for free download. This is a non-production version but is unlimited in terms of duration.
IBM has two strategies with respect to InfoSphere Streams. In the first place it wants to build a community of users, which is why it introduced the Quick Start Edition during 2013. Secondly, it wants to build ecosystems of applications, and partners building those applications. In this case, it is focusing on the telecommunications sector in the first instance, but expects to expand into other vertical markets as time progresses.
While IBM already has a number of partners for InfoSphere Streams, few of these will be known to readers. The most notable exception is with respect to IBM’s partnership with Datawatch. The latter is not a development partner but instead provides integration capabilities to external sources of data such as message queues—of course, IBM supports its own WebSphere MQ—but Datawatch provides the ability to access data from a variety of third party sources.
InfoSphere Streams has a diverse range of users. Early adopters of the technology included hospitals (neo-natal units), wind farms, and oil companies predicting the movement of ice floes, as well as a number of scientific deployments. More recently IBM has identified a number of repeatable and more commercially oriented use cases that it is now focusing on. In the short term, the company is focusing on the retail sector, particularly around data breaches, and the financial sector for fraud prevention and detection as well as risk analytics. Telecommunications is also a focus area but there are many others where InfoSphere Streams might be applicable, such as preventative maintenance and other applications deriving from the Internet of Things.
InfoSphere Streams is both a development and runtime environment for relevant analytics. In the case of the latter the product will run on a single server or across multiple, clustered servers depending on the scale of the environments and ingestion rates for real-time processing.
As far as development is concerned, when the product was originally launched it used a language called SPADE (stream processing application declarative engine) but it now supports SPL (stream processing language), which is SQLesque (indeed, the product supports IBM’s Big SQL). There is a conversion facility from SPADE to SPL. However, for most practical purposes all of this is under the covers as the product includes an Eclipse-based drag-and-drop graphical editor for building queries that business developers, in particular, will generally work with. Using this you drag and drop operators while the software automatically syncs the graphical view you are creating with the underlying (SPL) source code. Debugging capabilities are provided for those that want to work directly with SPL.
As an alternative you can create predictive models using SPSS Modeler and import these into the Streams environment via PMML (predictive modelling mark-up language) or using the native SPSS Modeler models and scoring libraries. The environment also supports both Java and R, the statistical programming language, and text analytics via natural language processing (which is good for sentiment analysis, intent to buy analyses and so forth). Finally, there is support for both geospatial and time-series capabilities with the former supporting location-based services and the latter providing a variety of analytic and other functions (including regressions) that are particularly relevant where data is time-stamped, which is especially relevant to the Internet of Things.
For data input, InfoSphere Streams supports MQTT (Message Queue Telemetry Transport), which is a lightweight messaging protocol that runs on top of TCP/IP, as well as WebSphere MQ and the open source Apache ActiveMQ. Other messaging protocols and feeds are supported through a partnership with Datawatch and there is also a RESTful API. There is also support for accessing data from back-end data sources such as the various IBM PureData products as well as third party data warehouses like HP Vertica.
For presentation purposes the product comes with a number of pre-defined graphical techniques that can be used to visualise information and these can be dynamically added at runtime, as required. In addition, you can use both IBM and third party data virtualisation products such as, in the case of IBM, Watson Explorer. There is also a facility to visually monitor applications while they are running.
In addition to the normal sorts of training and support services you would expect from any vendor (including extensive online resources), IBM offers business services (application innovation, business analytics, business strategy, functional expertise, mid-market expertise), IT services (application management, business continuity and resiliency, data centres, integrated communications, IT strategy and architecture, security), outsourcing services (business process outsourcing and IT outsourcing and hosting), asset recovery, hardware and software financing, IT lifecycle financing and commercial financing.
IBM PureData System for Analytics
Last Updated: 15th July 2014
The IBM PureData System for Analytics is a relational data warehouse appliance. It is the successor to the Netezza appliance acquired by IBM in 2010. The tag line reads "powered by Netezza technology". It is a massively parallel processing (MPP) database preinstalled and configured so it works with little or no on-site configuration. This was the differentiator Netezza established very successfully and which prompted the subsequent popularity of appliances or appliance-like products, not just for data warehousing but for other database applications.
IBM delivers the PureData System for Analytics through its global direct sales force. As well as plentiful reference customers in Telecommunications, Finance & Banking, Retail and Marketing Analytics, there does not seem to be any industry that is not penetrated to at least some extent.
Users span a wide set of analytics and reporting use cases, with particular growth in in-database analytics since the introduction of a wide range of analytics capabilities; for example support for R and a partnership with Revolution Analytics for their strong R-based algorithms.
Customers who adopt a 'logical data warehouse'—an extended data management architecture, comprising data in multiple formats and originating from multiple sources—sometimes describe the role of the PureData System for Analytics as the “relational data lake” in that architecture. Others are using it in more traditional warehousing roles; as data marts, multi-subject-area warehouses, central warehouses and any combination of these.
The major industries for the PureData System for Analytics appear to be Telecommunications, Finance & Banking and Retail, although there are also significant customer references in Marketing Analytics and most industries appear to be penetrated to at least some extent.
IBM is experiencing strong growth within existing large corporate accounts, as data volumes expand and more use cases are implemented. There is also strong growth in new accounts.
This suggests that the basic proposition—faster complex, analytic queries—has resonance in a wide range of situations. While scalability (see Technology) allows support of very large databases, the low entry point (1/4 rack) means that the PureData System for Analytics solution is also available to SMBs. Our research indicates that the 1/4 rack machine was specifically added to appeal in European markets where data volumes are typically lower and there is a greater tendency to start small and incrementally build.
The PureData System for Analytics is shipped in units of 1/4 rack, 1/2 rack, one rack, two racks, four racks and eight racks, which provides capacity for over 700Tb of user data on a single appliance.
The shared-nothing MPP architecture has been refined over a number of generations by IBM, based on the Netezza multi-core processors and patented FPGA (Field Programmable Gate Arrays) co-processor architecture. The FPGAs provide a unique way to stream query results from storage, avoiding pre-loading into memory. This has long been a successful technology for Netezza and, subsequently, IBM.
Recent iterations of the system have added additional performance-enhancing refinements such as columnar compression, snippet result caching, and large memory on processors. The PureData System for Analytics now ships with over 200 in-database analytic functions, including geo-spatial functions (provided by partner ESRI).
One further valuable addition is the ability for users to licence, and pay for, only part of the capacity of an appliance they have installed, so they have expandability built-in and can match investment more closely to their needs, eliminating the 'chunky' cost of acquisition. This feature is available from one rack and upwards. The physical 1/2 and 1/4 rack options provide downward scalability.
IBM offers a huge range of services, including application development, analytics, strategy, functional expertise, IT services, outsourcing, hosting and financing.
Since most PureData System for Analytics sales are into organisations with existing, transferable SQL database skills, adoption of the new platform is rarely a major issue.
IBM PureData System for Operational Analytics
Last Updated: 6th May 2013
The PureData System is based on the latest version of the p7 processor that was used in the 7700-based system but storage capacity has been increased with 900GB disks now being standard and solid state capacity has been similarly enhanced. Included within the PureData product are not just the hardware but also the latest version of AIX (7.1), InfoSphere Warehouse and its associated products (graphical and web-based tools for the development and execution of physical data models, data movement flows [SQW], OLAP analysis [Cubing Services] and data mining), DB2 (either v9.7 or v10), WebSphere Application Server, Optim Performance Manager (previously DB2 Performance Manager), Tivoli System Automation for Multi-platforms, and a new system console, as well as various other tools and utilities.
Apart from the focus on particular types of environment, as discussed, IBM does not have any particular vertical focus. Indeed, given the company's size you would expect it to be all-encompassing. However, it does offer specialised data models for a number of specific sectors, notably for banking, financial markets, healthcare, insurance, retail and telecommunications. It also offers a more generic pack for customer insight, market and campaign insight and for supply chain insight.
IBM has been a leading vendor in the (enterprise) data warehouse market since its inception. As such it has thousands of customers, both famous and not so famous. Historically it focused on the high end of the market but today it has offerings that scale down to less than 1TB.
The IBM PureData System for Operational Analytics is available in "T-shirt" sizes: extra small, small, medium, large, extra-large, and so on. At the bottom end the system consists of a "Foundation" module; and then you can add data modules, which each take up 1/3rd of a rack in any number you like up to 6 racks (that is, 18 data modules) - where each data module provides 62.4TB of raw data capacity. As far as failover is concerned, one failover module is required for each three data modules, with the proviso that you must have a failover module in each rack.
Notable features of the PureData System for Operational Analytics include advanced compression, piggy-back scans and multi-dimensional clustering. With v10.1 of DB2 you also get zigzag joins, continuous ingest and time-travel queries. Once DB2 v10.5 (released April 2013) is available as a part of this system (which we expect in due course), this will provide BLU Acceleration, which includes columnar storage, dynamic in-memory caching, parallel vector processing, data skipping and even more advanced compression. All of these features are designed to significantly improve performance.
Over the last decade or so there has been a significant shake-up in the data warehousing space. However, a clear pattern has now emerged. There are:
- Merchant database vendors that believe in a one-size-fits-all approach to both transaction processing and warehousing.
- IBM: a merchant database vendor that believes that you cannot get the best performance characteristics from a system that is supposed to cater to both transaction processing and analytics and which has therefore created specialised bundles for specific purposes, such as the PureData System for Operational Analytics.
- Traditional specialist data warehousing vendors that will compete with the PureData System for Operational Analytics.
- A host of newer (and some not so new) vendors that are really offering data marts rather than something that is suitable for use as an enterprise data warehouse.
In other words, the IBM PureData Systems for Operational Analytics faces exactly the same competitors as IBM data warehousing has faced historically. IBM has been successful over the last twenty years in acquiring a significant slice of the data warehousing market and we so no reason why that should change now.
In addition to the normal sorts of training and support services you would expect from any vendor, IBM offers business services (application innovation, business analytics, business strategy, functional expertise, midmarket expertise), IT services (application management, business continuity and resiliency, data centres, integrated communications, IT strategy and architecture, security), outsourcing services (business process outsourcing and IT outsourcing and hosting), asset recovery, hardware and software financing, IT lifecycle financing and commercial financing.
IBM Streams and Streaming Analytics
Last Updated: 6th December 2018
Mutable Award: Gold 2018
IBM Streams (previously IBM InfoSphere Streams) is a high performance, low latency platform for analysing and scoring data in real-time. It is a part of the Watson & Cloud Platforms. In addition to the main Streams product (currently in version 4.2.x) IBM also offers a Quick Start Edition that is available for free download. This is a non-production version but is unlimited in terms of duration. There is also a cloud-based offering, called IBM Streaming Analytics, that runs on IBM Cloud; there is an optional “lite” version that allows up to 50 free hours usage per month.
IBM Streams is both a development and runtime environment for relevant analytics. In the case of the latter the product will run on a single server or across multiple, clustered servers depending on the scale of the environments and ingestion rates required for real-time processing. There is also a Java-based version developed to run on edge devices, which has been open-sourced as Apache Edgent. This requires a Java Virtual Machine (JVM) but is otherwise very lightweight. It supports Kafka and MQTT (Message Queue Telemetry Transport) as does Streams, and you can push down analytic functions from Streams into Edgent.
Customer Quotes
"Once we had settled on IBM Streams, we were able to plug in the statistical models developed by our data scientists and embark on a rapid proof of concept, which went very well. From there, we were able to industrialize the solution in just a few months."
Cerner Corporation
"IBM Streams increases accuracy of Hypoglycemic event prediction to ~ 90% accuracy with a three-hour lead time over base rate of 80%."
Medtronic
"With our partner, IBM, we are leveraging the power of the unstructured and structured data through streaming and cognitive capabilities to position ourselves effectively to meet the needs of our customers."
Verizon
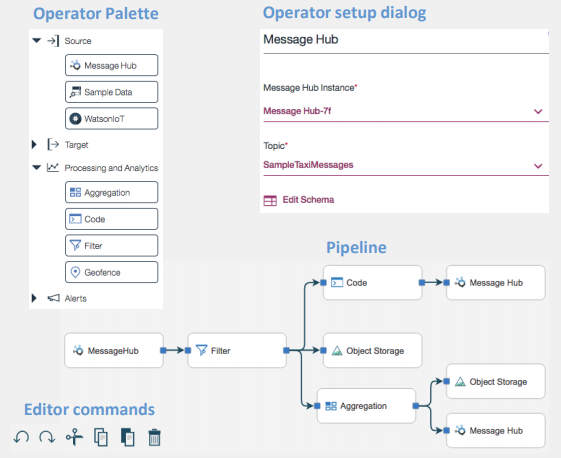
Figure 1 – Flow Editing in Streams Designer
Typical use cases for IBM Streams involve looking for patterns of activity (such as fraud), or exceptions to expected patterns (data breaches) or to find meaningful information out of what otherwise might be considered noise (six sigma), as well as commercial applications such as analysing how customers are using their cell phones, or to support Internet of Things (IoT) applications such as predictive maintenance.
As stated, the product is both a development and deployment platform. The latter has been discussed. As far as the former is concerned the product primarily supports SPL (stream processing language), which is a SQL-like declarative language. However, for most practical purposes this is under the covers as the product includes an Eclipse-based drag-and-drop graphical editor (Streams Studio) for building queries. Using this you drag and drop operators (which include functions such as record-by-record processing, sliding and tumbling windows, and so on) while the software automatically syncs the graphical view you are creating with the underlying (SPL) source code. Debugging capabilities are provided for those that want to develop directly with SPL. In addition to SPL, Streams Studio also supports development in Java, Python and Scala (via a Java API). SPL will typically outperform Python (for example) as SPL is written and compiled in C whereas much of Python (for example) is interpreted.
Currently in beta, an alternative called Streams Designer offers a web-based environment, which is reputedly easier to use. While the current Streams Studio is usable by business analysts we expect Streams Designer (Figure 1 illustrates flow editing in Streams Designer) to be more popular amongst this constituency.
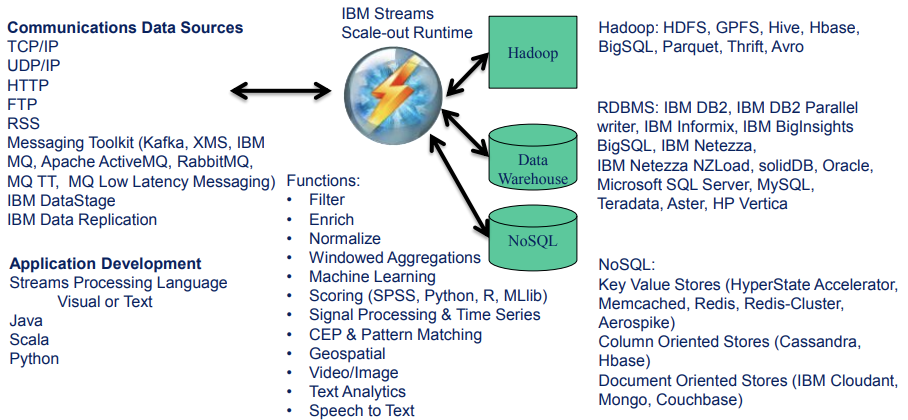
Figure 2 – Functions and connectivity offered by IBM Streams
Figure 2 illustrates some of the functions of IBM Streams as well as the connectivity options that are available. There are, however, notable capabilities omitted from the figure. In terms of functions these include integration with IBM’s rules engine and the ability to do deep packet inspection. There is also no mention of the Db2 Event Store, which can be used to persist events. Figure 2 also fails to cover support for PMML (predictive modelling mark-up language) for model scoring portability. It is also worth mentioning integration with Apache Beam (via an API), which is a software development kit (SDK) for constructing streaming pipelines. This would be as alternative to using Streams Designer. Finally, but by no means least, IBM Streams is delivered with some twenty pre-built machine learning algorithms. These are typically packaged into toolkits for specific verticals, such as cybersecurity.
The ability to ingest and analyse data in real-time is fundamental to many existing and developing environments. The most commonly cited are fraud applications on the one hand and Internet of Things based applications on the other. However, while IBM Streams is clearly one of the market leaders when it comes to both performance and analytics capability for such conventional capabilities, it has also been extended into areas that other vendors cannot reach. As one example, Streams leverages IBM Watson’s speech to text capabilities (for call centres, for example); as another, IBM is making significant contributions in the medical arena, and not just with respect to Medtronic example quoted. It is also worth noting the internationalisation of Streams, which is available both in single byte and double byte languages.
The Bottom Line
IBM Streams was not the earliest product to be introduced into this market but it is almost a decade old. While modernisation is always an ongoing requirement, the enterprise-class features you require come from the sort of maturity that IBM has in spades.
Mutable Award: Gold 2018
IBM Test Data Management
Last Updated: 18th June 2019
Mutable Award: Gold 2019
There are several IBM products that contribute to test data management. The most prominent belong to the IBM InfoSphere Optim range of products, including Test Data Management, Data Privacy, Test Data Fabrication and Test Data Orchestrator. These products handle data subsetting and masking, synthetic data generation, and test data coverage. InfoSphere Information Analyzer is also available as a data discovery tool that integrates with the Optim suite. Finally, IBM now provides data virtualisation via InfoSphere Virtual Data Pipeline, a white-label product created by Actifio, a close partner of IBM.
These products provide a range of connectivity options that most recently includes integration with Azure DB and Apache Hive. In addition, Optim is available as a native solution for z/OS mainframes.
Customer Quotes
“The IBM solution empowers us to keep our clients’ personal data safe, protecting the company’s reputation and preserving our customers’ trust.”
CZ
“Being able to test and iterate faster – using realistic, desensitized data across multiple applications – allows our teams to deliver leading-edge solutions that help our business run better and that bring greater security and convenience to our customers.”
Rabobank
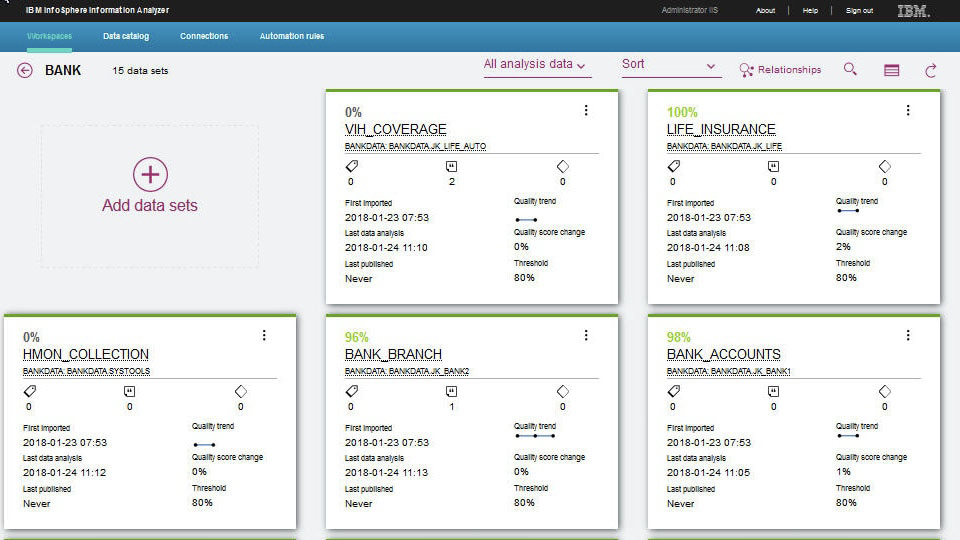
Fig 1 IBM InfoSphere Information Analyzer
IBM provides data discovery via InfoSphere Information Analyzer, as seen in Figure 1. This product profiles and classifies the data, and relationships between data, within your system. This includes the discovery of sensitive data. Both column names and data values are used to classify your data, and you can add custom field classifications if you wish or use the out of the box defaults. Using the product with Optim allows you to create meaningful subsets of your data, mask sensitive data, and automatically create representative sets of synthetic data.
Subsetting is accomplished via InfoSphere Optim Test Data Management. Test Data Management allows you to extract representative, meaningful subsets of your data, which can additionally be right-sized by test type. For example, you might want a different sized subset for, say, unit testing as opposed to integration testing. Facilities are provided to refresh test data when required and also to compare data subsets. Multiple data sources can be integrated, and a single subset extracted from all of them. Note that although there are some performance issues on data sources without transactional indexes (such as Hadoop), these issues have been acknowledged by IBM and are currently being addressed.
InfoSphere Optim Data Privacy is a data masking product with several notable features, including affinity masking (for example, maintaining case), consistent masking across multiple platforms while preserving referential integrity, and semantic masking, though the latter is not easy to use and is not enabled for test data management. The company has also implemented in-database masking in a number of its environments and is actively extending this to others. This is supported by user defined functions. IBM is also actively integrating masking into other environments (for example, there is a Data Masking Stage in DataStage). You can use Optim, which supports both mainframe and distributed environments, for dynamic data masking but this is more usually the domain of IBM Guardium. Although Data Privacy does not support unstructured data in and of itself, IBM is able to provide this via their partnership with ABMartin.
InfoSphere Optim Test Data Fabrication, released in August 2017, offers synthetic data generation. It creates this data based on declarative rules that describe the desired dataset. Contradictory or unsatisfiable sets of rules are detected and highlighted. You can create these rules from scratch, but the more appealing option is to import metadata from Information Analyzer. In this case, a selection of rules will be created automatically that will generate synthetic data that is representative of the real data profiled by Information Analyzer. In addition, any column that Information Analyzer successfully classifies can be fabricated via built-in functions available in Test Data Fabrication.
InfoSphere Optim Test Data Orchestrator is a tool for measuring test data coverage that will analyse your test data, determine which possible combinations are missing, and present the results in a coverage matrix. Moreover, it allows you to create rules that express the smallest set of test data that is relevant to your system and will then then generate a coverage matrix purely for the data expressed by those rules. This provides a much more meaningful metric for test data coverage. Notably, the product is designed for collaboration, the idea being that the aforementioned rules will be determined by testers and subject matter experts working together.
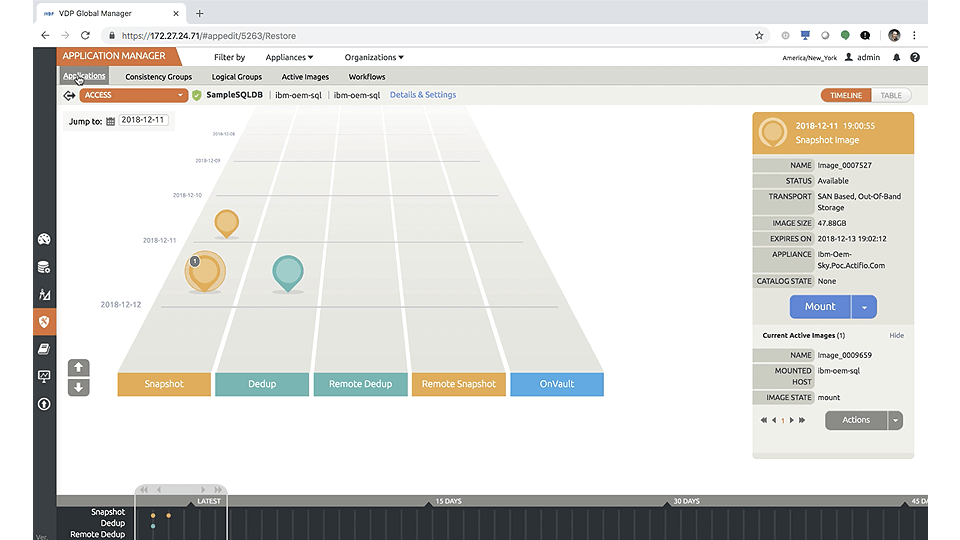
Fig 2 IBM InfoSphere Virtual Data Pipeline
Finally, InfoSphere Virtual Data Pipeline, introduced in December 2018 and shown in Figure 2, provides data virtualisation. This means that it can create and distribute virtual copies of your test data nearly instantly, whether that data consists of an entire (masked) production database, a masked or unmasked subset, or a synthetic dataset. These copies only store differences between themselves and the original data set, meaning that initially they take up no additional space (and what’s more, later increases in space tend to be minimal). Virtual Data Pipeline distributes these copies via self-service, and refreshes them automatically and on a schedule.
The most obvious differentiator for IBM’s test data management offering is its completeness: IBM is the only vendor we know of that is offering subsetting, masking, synthetic data and data virtualisation. Data virtualisation, in particular, is quite a rare capability, and IBM is the first vendor we have seen that offers it without almost exclusively focusing on it. Moreover, data virtualisation is a very powerful capability. The rapid provisioning it offers in combination with self-service can have a marked improvement on tester productivity, and it offers a very significant reduction in the space needed to store your test data.
It’s also worth noting the unique approaches taken by Test Data Fabrication and Test Data Orchestrator. Creating your synthetic dataset using declarative rules is useful, as is the ability to create data that is automatically representative of your production data. Likewise, paring down test data coverage to relevant test data coverage allows you to maximise coverage where it matters.
The Bottom Line
IBM offers a very complete test data management solution that is particularly appealing if you want to combine data virtualisation with either data subsetting or synthetic data generation.
Mutable Award: Gold 2019

IBM Watson Knowledge Catalog
Last Updated: 14th July 2020
IBM Watson Knowledge Catalog, itself part of IBM Cloud Pak for Data, is a data catalogue and data governance solution that promises to help you deliver ‘business-ready’ data across your enterprise: data that is meaningful, trustworthy, accessible, secure, and of high quality. In other words, data that is ready for consumption. What’s more, it does so through a single, unified governance experience.

Fig 01 - Services provided through IBM Watson Knowledge Catalog
It achieves this by positioning the catalogue itself at the centre of a range of relevant services, including AI-driven metadata curation; automated governance, data quality and policy management; and self-service data access, data preparation, and collaboration. The full extent of these services is shown in Figure 1, and the overall effect is to transform what might otherwise just be a data catalogue into a fully fledged data governance solution.
Watson Knowledge Catalog exposes your data assets for consumption by your users. From a user’s perspective, the product offers search access, asset recommendations, data previews, lineage information, and collaborative features such as commenting, reviews and ratings. In addition, users are able to bring data assets into their own projects, refine and enrich them, then use them to create visualisations or new data sets that can be shared both within and without the catalogue itself.
The product also features data virtualisation, meaning that all of your enterprise data can be accessed in the same way regardless of its physical location. The catalogue thus provides a single view for all of your enterprise data. This effect is enhanced by the ability to bring business assets, such as BI reports and data models, into the catalogue as well.
From the more administrative side of things, role management, role-based views, workflows and approval processes are all supported. Moreover, data assets can, in fact, be exposed to your users through multiple different catalogues that you can control access to individually. The intention is that each catalogue will contain a particular subset of your data assets, allowing you to provide information that is targeted at a particular selection of your users. This makes their lives easier by hiding information that is extraneous to them while improving data security by exposing information only as necessary.
However, before you deliver your data to your users, you will want to be able to curate and govern it. To this end, the product enables you to create and manage a foundational layer of business terms (in other words, a business glossary), rules, policies, data classes (a number of which are available out of the box) and reference data. These can be associated to your data assets, providing the latter with concrete business meaning and context that can be explored and searched on. Moreover, these associations are used to drive the product’s automated discovery and classification services, as well as its data protection rule framework.
A particularly notable example of the former is Watson Knowledge Catalog’s ability to automate the onboarding of new data. When the catalogue ingests new data, it can (at your option) automatically classify it into data classes, identify any common data quality problems within it, and assign business terms to it. This functionality is presently restricted to structured data, although there are certainly other IBM products that will handle discovery on unstructured data.
As for the data protection rule framework, Watson Knowledge Catalog actually categorises your rules into two distinct categories: governance rules and data protection rules. The former are purely informational, and hence primarily act as a way to describe and document your policies in easily understood and concrete terms. Data protection rules, on the other hand, are actionable: they can be enforced automatically by the catalogue wherever they apply. They are created using a rule builder, and are generally used to protect your sensitive data (for example, by masking it) before it is exposed to your users. They apply to data exposed within the catalogue as well as data exported from or otherwise shared beyond it.
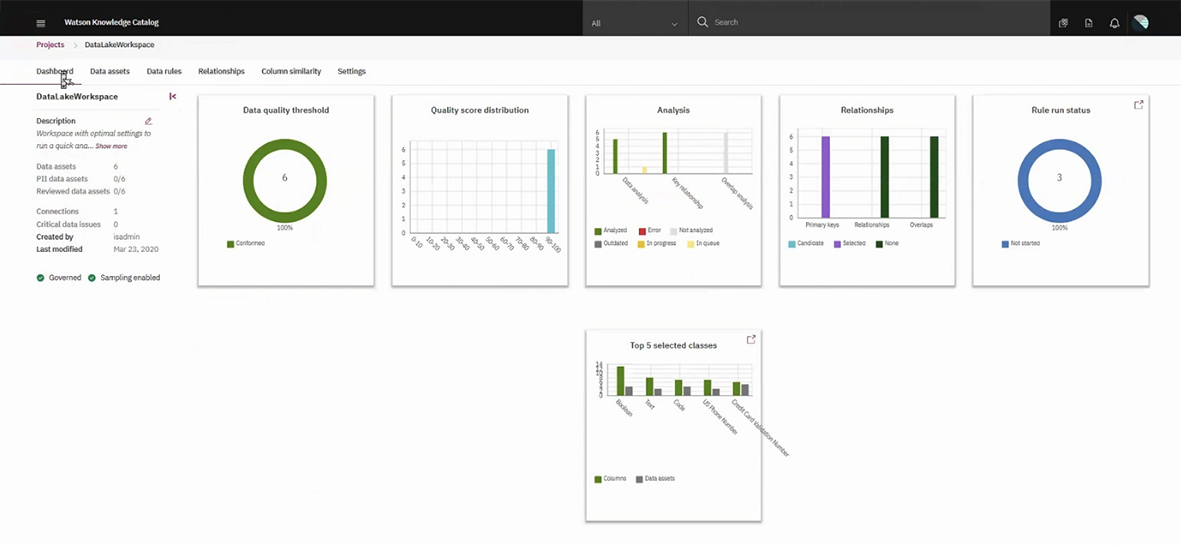
Fig 02 - Data quality dashboard in IBM Watson Knowledge Catalog
Watson Knowledge Catalog also uses a variety of different data quality dimensions (such as data duplication, data type violations, and so on) to measure the data quality of your data assets and assign to each of them a data quality score. This is displayed visually within a data quality dashboard (see Figure 2) that can be drilled down into to view more detailed data quality information pertaining to individual data assets.
Watson Knowledge Catalog provides a comprehensive data governance solution built around the core capability of the data catalogue. It offers an impressive amount of automated functionality, with the fully automated discovery and onboarding procedure being particularly noteworthy. The data virtualisation provided by the product is also highly effective, and combined with the aforementioned onboarding process, you can easily ingest numerous data sources in a curated fashion and access all of the resulting data in a single location.
Data protection rules are another notable example of automation in service of governance, and an especially useful one in light of GDPR and other regulations that demand an enhanced degree of data privacy and data security. What’s more, splitting rules into two categories based on their use is a sensible way of making them easier to understand and comprehend as a whole.
The ability to create multiple fit for purpose catalogues may also be useful, especially in large organisations that may have departments with radically different data needs (although it does run the risk of creating or reinforcing data silos).
The Bottom Line
IBM Watson Knowledge Catalog is a mature and highly competent data governance solution with an impressive variety of automated capabilities.

IBM Watson OpenScale
Last Updated: 17th January 2020
IBM Watson OpenScale is a platform that is specifically targeted at operationalising AI (augmented intelligence) models. It runs on both IBM Cloud and IBM Cloud Private, and it integrates with any tools for building and running AI, from competitive offerings like Microsoft Azure ML and Amazon ML, to open source environments such as TensorFlow or Spark, to IBM’s own tools, Watson Studio and Watson Machine Learning.
Customer Quotes
“IBM also makes available, as open source products, AI Fairness 360, which provides bias detection and mitigation, and the Adversarial Robustness Toolkit, which helps to prevent model hacking.”
“Watson Machine Learning (and IBM SPSS) provides complementary facilities for monitoring model performance, model management capabilities, and the Experiment Assistant, which is a suite of tools for managing model training. Workflow to support functions such as approval processes are built into the various IBM platforms upon which Watson OpenScale runs.”
Watson OpenScale has various capabilities that enable business to operate and automate AI across its lifecycle, with the aim of bringing enterprise-scale AJ more easily within reach. First, the product allows you to monitor how the deployment of AI is affecting business outcomes, whether positively or negatively, no matter where models were developed or deployed.
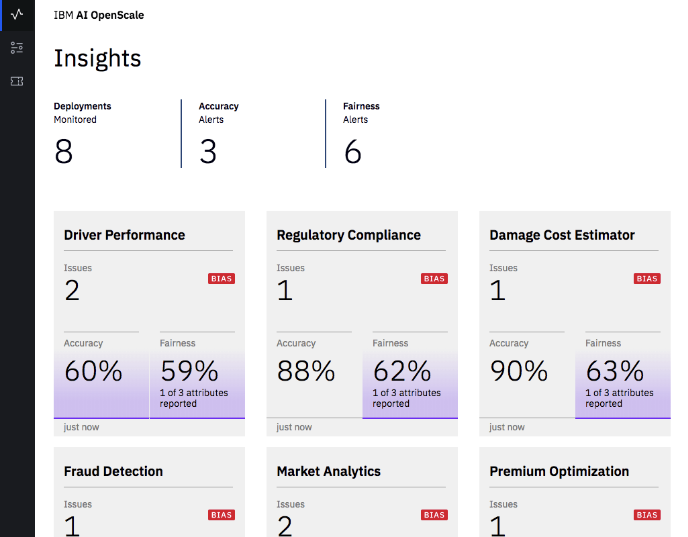
Fig 01 - OpenScale dashboard
Figure 1 shows a dashboard that is used to automatically detect unfair or inaccurate results based on user-defined conditions. As can be seen in this example, “driver performance” has two issues: it is both inaccurate (that is, performing badly) and is producing unfair outcomes. In total there are three accuracy alerts and six bias alerts.
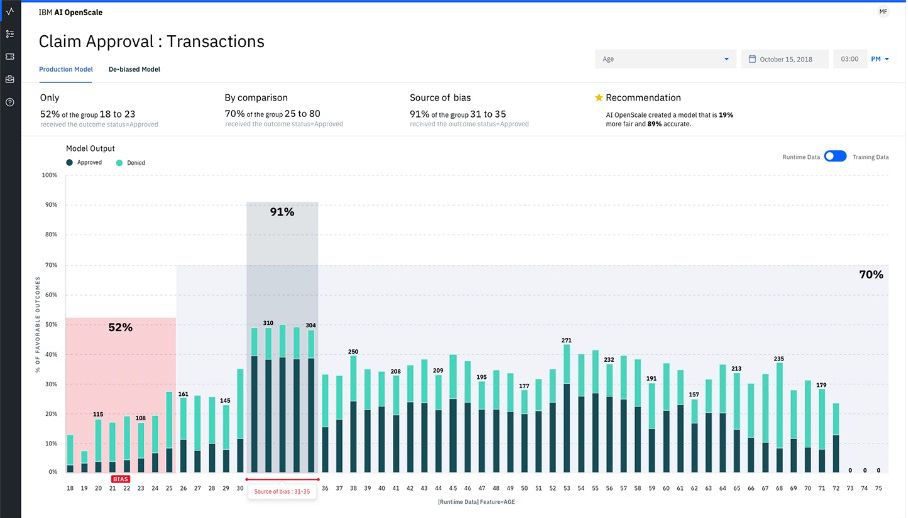
Fig 02 - OpenScale detect and mitigate function
A second function of Watson OpenScale is to detect, and automatically mitigate, bias: see Figure 2. Various companies have announced such capabilities for training purposes but, as far as we know, Watson OpenScale is the only such product that is also available at run-time, when it compares the performance of the deployed models with recommended de-biased models. No retraining is required. However, it will provide a way for a user to download and inspect the de-biased model before deploying it into production.
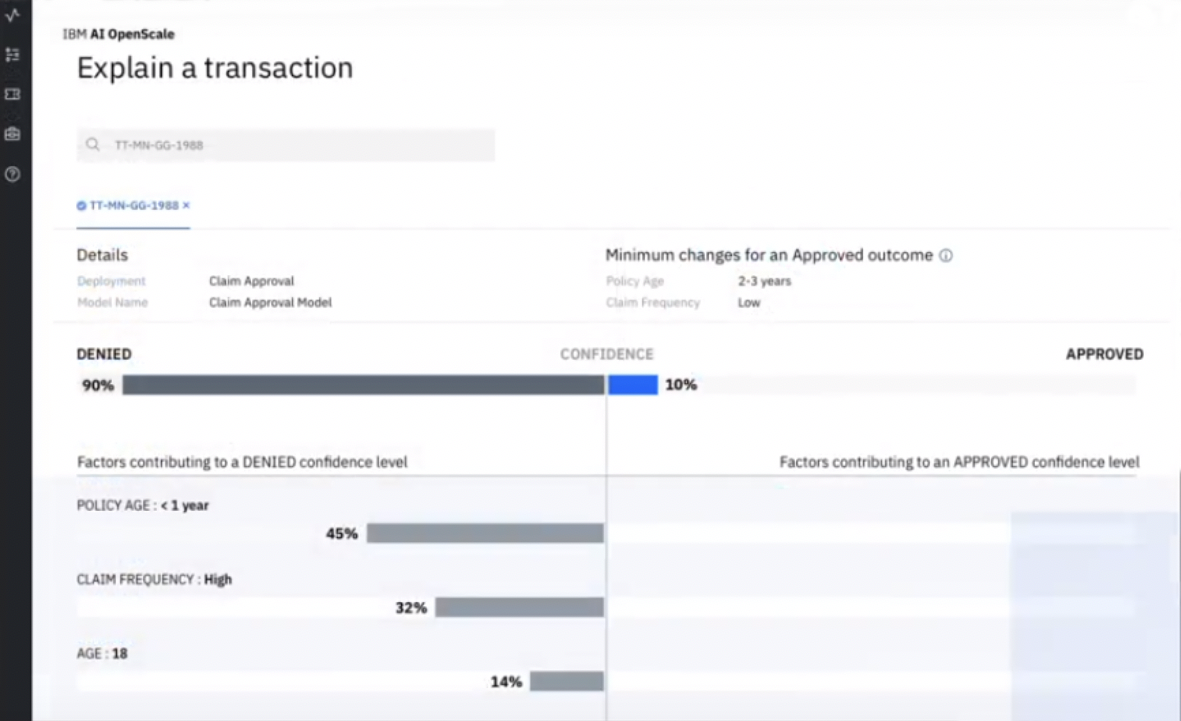
Fig 03 - OpenScale explainability function
Thirdly, in addition to audit capabilities that allow you to trace the recommendation any decision, Watson OpenScale provides an explainability function. This is illustrated in Figure 3. It allows you to explore the factors involved in any decision from AI, how much those factors contributed to the decision and how different factors might have changed the outcome. As can be seen, this also provides a confidence level for the transaction in question, and the ability for the business to explain a decision to a customer, regulatory body or other party.
Under the covers the product also provides what is known as payload logging. This means that all the data being scored is logged and persisted to a database and it is against this data that the various dashboards and other capabilities of Watson OpenScale are based. You can query the database using IBM Cognos or using third party tools such as Looker or Tableau, in order to get performance metrics. In addition, these metrics can also be exported and combined with application metrics to measure business outcomes.
AnalyticOps concerns the operationalisation, monitoring, improvement, management and governance of augmented intelligent models.
As AI becomes more widely deployed, AnalyticOps capabilities will become more vital. Where most companies today have a handful of deployed models and applications, if that, we expect large organisations to have thousands or tens of thousands of models to deploy and manage in the not-too-distant future. This is going to be impractical without tools of the type described here.
The Bottom Line
IBM is one of only a handful of vendors to offer end-to-end model management, despite the fact that this is a technology that has been around for a long time. It is one of even fewer companies that is actively addressing operationalisation in order to connect the work done by a data scientist to business owners, in business terms. Indeed, IBM is taking a lead in so far as its ethical positioning is concerned. We know of no other company that offers bias detection and mitigation along with explainability tools. We are very impressed.
InfoSphere Guardium
Last Updated: 29th October 2014
IBM’s Guardium products are part of its InfoSphere platform, designed for trusted information purposes. The platform includes data integration, data warehousing, master data management, big data and information governance.
Within InfoSphere, the Guardium products are part of IBM’s overall information integration and governance strategy and are designed to help organisations with their data security and privacy needs. Within the Guardium products are centralised controls for data privacy and security, database activity monitoring, including data masking, data encryption and redaction, and vulnerability assessment. Guardium was originally acquired by IBM in 2009.
The Guardium products are designed to address the data security and compliance lifecycle. Core capabilities include protecting both structured and unstructured information in databases, data warehouses and file shares, to capture, analyse and monitor data traffic, enforce access controls, monitor and enforce policies, find and classify sensitive data, find and analyse vulnerabilities, and support forensic investigations. It offers a central management console and full audit capabilities for governance and compliance purposes, along with a dashboard for tracking and resolving data security problems.
Although IBM states that its InfoSphere Guardium products can help organisations streamline operations regardless of their size, these products are generally used by large enterprises, often multinationals with worldwide operations. It claims this product family scales to support tens of thousands of databases in an organisation, including those on-premise, in the cloud or in Hadoop environments for big data.
The Guardium family of products can be purchased in a modular fashion, allowing organisations to choose individual products from within the portfolio, as well as to mix them with components from any other vendor.
These products are aimed at large enterprises that face pressing security and regulatory compliance concerns. In a video on its website, IBM states that its InfoSphere Guardium products are used by some 600 organisations worldwide, including the majority of the top banks, managed healthcare providers, retailers, insurers and telecommunications companies globally.
Designed to protect trusted information in databases, InfoSphere Guardium supports all major database management platforms and protocols on all the major operating systems, as well as a growing range of file and document sharing environments. It also supports a number of enterprise business suites, including those from Oracle and SAP.
InfoSphere Guardium is based on a multi-tier architecture, using connector appliances to gather data from systems under management, which are then collected in a central management console where the data is aggregated and normalised, providing an audit trail and secure management and enforcement of policies. No changes are required to the configurations of systems under management and all functions are managed in one central repository. For creating greater security intelligence, Guardium interfaces with a number of other systems, including LDAP directories for access control, email, change ticketing and SIEM systems.
In addition to the normal sorts of training and support services you would expect from any vendor, IBM offers business services (application innovation, business analytics, business strategy, functional expertise, mid-market expertise), IT services (application management, business continuity and resiliency, data centres, integrated communications, IT strategy and architecture, security), outsourcing services (business process outsourcing and IT outsourcing and hosting), asset recovery, hardware and software financing, IT lifecycle financing and commercial financing.
InfoSphere Information Server
Last Updated: 27th November 2014
InfoSphere Information Server is IBM’s data integration platform. It supports the whole spectrum of use cases for data integration including application to application integration, B2B integration, ETL (extract, transform and load) and ELT for moving data from one environment to another (from operational systems to a data warehouse is the classic case, nowadays including moving data into Hadoop), data migration and SaaS (software as a service) implementations. In this latter case IBM offers specific capabilities with regard to some third party applications, notably Salesforce.com.
There are also specific editions of InfoSphere Information Server, including; InfoSphere Information Server Enterprise Edition, InfoSphere Information Server Enterprise Hypervisor Edition, InfoSphere Information Server for Data Integration, InfoSphere Information Governance Catalog, and InfoSphere Information Server for Data Quality (which provides data profiling and data cleansing capabilities). There are also editions for data warehousing and for SAP implementations. We are slightly surprised that there is no particular edition for data migration and/or archiving, where you would probably require IBM InfoSphere Discovery as opposed to IBM Information Analyzer, which you get in the Information Server for Data Quality Edition. However, we understand that InfoSphere Discovery and Information Analyzer will be merged during the course of 2015, which will make this unnecessary.
IBM delivers InfoSphere Information Server through its global direct sales force.
As a product that is around 20 years old (InfoSphere DataStage, as it was then, was originally developed by Ardent, which was acquired by Ascential, which in turn was acquired by IBM) there are thousands of users of InfoSphere Information Server and there are a number of case studies published by IBM on its web site, including the company’s own implementation in the office of the CIO, as well as banking customers, universities and others.
Perhaps the most significant aspect of InfoSphere Information Server, outside its role of physically moving and transforming data at scale (including big data integration and grid deployments), is the extent to which it plays a part in information governance. Thus the product includes the ability to define governance policies and rules, a data governance dashboard, integration with InfoSphere Master Data Management, Blueprint Director (used to model and view the integration and governance architecture) and the Information Governance Catalog (previously Business Information Exchange), which provides a business glossary and metadata workbench. There is also a new lineage viewer.
Alongside core capabilities (for example, new connectors to the cloud) the emphasis in the data integration market at present is very much on self-service capabilities, just as the same is true for business intelligence. InfoSphere Information Server provides this with InfoSphere Data Click, which is a simple web-based interface for on-demand integration, both between conventional sources but also for access data lakes (integration with Hadoop is built into the product). However, self-service is not only about the user experience, it is also about automating functions that underpin what the user can do. Thus, for example, Information Server supports the idea that you can move data into, say, an IBM data warehouse using ETL at one time of the day and ELT at another time of the day. However, this has to be manually scheduled and it would be preferable if there was an optimiser built into the product to automate this and other processes. We understand that such an optimiser is planned. We should also add that this is not a criticism—other vendors in this space do not, typically, have even the existing level of automation that IBM provides. Other self-service capabilities include smart hover (which provides contextual details about an asset when you hover your mouse over it) and semantic search capabilities. There are also new facilities in the latest version (11.3) to support cross-team collaboration.
In addition to the normal sorts of training and support services you would expect from any vendor (which includes extensive online resources), IBM offers business services (application innovation, business analytics, business strategy, functional expertise, mid-market expertise), IT services (application management, business continuity and resiliency, data centres, integrated communications, IT strategy and architecture, security), outsourcing services (business process out-sourcing and IT outsourcing and hosting), asset recovery, hardware and software financing, IT lifecycle financing and commercial financing.

Rational Requirements Composer
Last Updated: 27th May 2013
IBM Rational Requirements Composer is a 'next generation' requirements management tool - it is part of IBM's Collaborative Life-cycle Management tool-set on the Jazz platform. It claims to use 'just enough' process, in conjunction with a web-based application, to let you manage requirements effectively for iterative, waterfall and agile-at-scale development methodologies (always remembering that true Waterfall was always intended to be an iterative process, of course). It emphasises agile delivery of business outcomes through collaborative development by global teams: enabling all stakeholders (including the customer sponsor, users, marketing, legal and compliance, finance, education, operations and developers) to achieve rapid consensus on requirements and their priority - which could contribute to a DevOps culture.
Requirements Composer supports requirements capture; traceability; collaborative review; visual requirements definition; progress and status reporting; and an audit history of changes to requirements. It can be seen as complementing IBM's other requirements management tools by adding collaboration, capture and visual modelling capabilities on top of their requirements management capabilities.
Rational Requirements Composer is available, and supported, globally. Licenses can be bought through normal IBM channels. However it can also be downloaded from jazz.net and potential users can try it out in a web-based 'sandbox' environment, from a web browser, Eclipse client, Visual Studio client etc.; and potential collaborators can be invited to join in the trial.
Requirements Composer is aimed at Agile developers in the enterprise, especially those aiming for 'agile at scale'. However, it is available to a much wider community than this via jazz.net on the web.
Rational Requirements Composer is a web application running on a wide range of desktops: Windows or various flavours of Linux. Its server runs on various flavours of Linux, on Windows Server, Sun Solaris, AIX IBM Power System and VMWare. It uses a wide range of databases to hold requirements data and metadata; Apache Derby is included but D2, Oracle and SQL Server are also supported. Apache Tomcat application server is included, but WebSphere is also supported
It supports the Open Services for Life-cycle Collaboration (OSLC) specifications, so it can integrate with a range of development tools from IBM (and, potentially, other vendors).
What this all means is that Rational Requirements Composer isn't dependent on being deployed in all-IBM environments, which might not have been so true of past IBM tools.
IBM offers all the services (consultancy, training etc.), available across the globe, that one might expect to need in support of this product.
Paricularly noteworthy is the Jazz Community at jazz.net, which represents IBM's next generation of interactive, collaborative tools for delivering buisiness outcomer from smarter automated systems. jazz.net is a lot more than a conventional product support site and according to IBM "we use our products to build our products, right here at Jazz.net. You can track our plans, talk to the developers, and try our latest stuff. Help us build the tools that you're dreaming about!". There does, indeed, seem to be a buzz around jazz.net.
Rational Requirements Composer is also part of the OSLC (Open Services for Lifecycle Collaboration) community for tool integration
A wide range of training courses, both classroom and e-Learning, for Rational Requirements Composer are available from IBM and its partners.
Rational Test Virtualization Server
Last Updated: 17th December 2018
Rational Test Virtualization Server (RTVS) is IBM’s service virtualisation offering. It is part of the company’s Rational Test Workbench, a suite of products that are designed to provide a complete continuous testing solution. The suite also includes a variety of products for enabling functional, performance and API testing and, as you might imagine, these products are well integrated. The Rational Test Workbench is in turn part of IBM DevOps, the branch of IBM devoted to providing products that enable continuous delivery and digital transformation.
Customer Quotes
“IBM Rational Test Workbench software lends itself to complex environments. We use it to test across platforms, which significantly cuts the time required to roll out applications.”
Banking company
“The bottom line: service virtualisation reduces your cost and accelerates development, and that’s what companies need to stay ahead of their competition.”
Sandhata
Figure 1 – Incremental integration testing
There are multiple ways to create a virtual service in RTVS. The most straightforward is to record and playback requests and responses to and from a real service. Alternatively, you can import existing definition files (for example, Swagger specifications) or create your virtual service from scratch in ECMAScript. More interestingly, RTVS provides you the option to, in conjunction with the aforementioned recording, examine and ‘synchronise’ with the System Under Test (SUT). This allows RTVS to create both physical and logical models of the SUT, mapping out, respectively, the physical and logical dependencies within your system. The latter will be more pertinent the majority of the time, allowing you to see, graphically, the different services within the SUT and how they depend on each other. This is useful for helping both technical and non-technical users understand the SUT. More importantly, RTVS allows you to create any number of virtual services based on this model without writing any code (although they may be supplemented with scripting in ECMAScript or Groovy if desired).
RTVS provides extremely broad support for messaging protocols and message formats, the full list including more than 30 different technologies. It can also virtualise systems in addition to services. This includes products from SAP, TIBCO and, of course, IBM, as well as mainframes. This means that you can test against virtual copies of these systems just as you would a regular virtual service. The product also features sophisticated sifting and passthrough technology, allowing you to, for example, use a virtual service to capture and respond to data that is coming from a particular source, allowing all other requests to pass through to the real service behind it. In addition, RTVS allows you to model the response times of your virtual services on real data, ensuring that they are realistic.
Virtual services created in RTVS can be published to a virtual service repository. This is a store of virtual services, available throughout the enterprise, that is intended to promote the reuse of virtual services by both technical and non-technical users. It is accessed through a browser, allowing all users in your organisation to configure and deploy virtual services as needed. In addition, RTVS supports what IBM calls ‘Incremental Integration Testing’. The principle idea here is that you start out by testing a single, isolated part of your system, virtualising all components of your system that exist outside of this part. Then, gradually, you replace these virtual components with real ones, testing as each service is replaced. This allows you to test gradually and methodically, rather than having to test everything, together, at once. RTVS enhances this methodology by enabling a technologically seamless transition between virtual and real services, owing to their shared interfaces.
Testing is an extremely important part of the software development lifecycle. With software products increasingly developed within an extensive ecosystem of APIs and other services, service virtualisation has become a necessity in order to test your software in isolation of the other components within your system. It is also important for continuous testing, as virtual services, unlike real ones, do not experience downtime. In addition, if you are utilising third party services that charge by usage, using them during testing is an unnecessary expense that can be avoided with service virtualisation.
RTVS stands out for a number of reasons. Incremental integration testing allows you to test parts of your software in isolation before integrating them bit by bit. This allows for a gradual and controlled integration testing process, and is particularly helpful if, for example, you have multiple teams developing co-dependent software. With RTVS, each team can test their software against a virtual copy of the others’, then seamlessly slot in the real software when it is ready. The ability to virtualise systems – particularly mainframes – is another notable feature. A significant number of organisations have legacy systems that cannot be disrupted under any circumstances, and therefore can be difficult to test against. RTVS can virtualise these systems, allowing for effective testing in these environments. Finally, it should be noted that both the visual model of your system and the virtual service repository that RTVS creates are helpful for enabling effective collaboration on virtual services throughout your enterprise.
The Bottom Line
As part of the Rational Test Workbench, RTVS forms a significant part of a complete continuous testing solution. Even apart from it, it is a competent service virtualisation product with several interesting and innovative features. If these features are relevant to you – and there is every reason at least some of them should be – we urge you to consider adding RTVS to your shortlist.
Commentary
Solutions
- IBM Cloud
- IBM Cloud Pak for Data
- IBM Db2 Event Store
- IBM Doors
- IBM Informix
- IBM Informix Warehouse Accelerator
- IBM InfoSphere Discovery
- IBM InfoSphere Optim Test Data Management
- IBM InfoSphere Streams
- IBM PureData System for Analytics
- IBM PureData System for Operational Analytics
- IBM Streams and Streaming Analytics
- IBM Test Data Management
- IBM Watson Knowledge Catalog
- IBM Watson OpenScale
- InfoSphere Guardium
- InfoSphere Information Server
- Rational Requirements Composer
- Rational Test Virtualization Server
- IBM BigInsights
- IBM Blockchain as a service
- IBM Bluemix
- IBM Cloudant
- IBM DashDB
- IBM DataWorks
- IBM DB2
- IBM InfoSphere Master Data Management
- IBM Security QRadar
- IBM Softlayer
- IBM Watson Analytics
- IBM Watson Content Analytics
- IBM Watson Engagement Advisor
- IBM Watson Explorer
- IBM Watson User Modeling
- IBM Websphere
Research

Data Governance (2024)

IBM Launches Data Product Hub

Data Fabric

Test Data Management (2024)

Master Data Governance (2023)

Master Data Management (2023)

Generative AI Value & Limitations
